おうちサーバ無料監視 by Grafana Cloud
TL; DR
- Grafana Cloudは無料枠が大きく個人でも使いやすい
- メトリクス・ログ・アラートに加えトレースまで扱える
- Grafana Agentをnon-rootで動かしていると埋め込みのcAdvisorでは正しくメトリックを拾えない事があるので別途立てると良い
- みんな構造化ログにしてくれ
おうちサーバも監視したい
昨今は安価なミニPCでも十分な性能が出るようになってきており、特に中国製のミニPCがコスパの良さから注目されています。これにより自宅におうちサーバとして置いたり、複数購入してKubernetesクラスタを組むなどが安価でできるようになり、私の周りではにわかに盛り上がりを見せています。
ある程度サーバを運用していると死活監視やディスク容量の警告、ログの検索などが欲しくなります。昨今ではOSSでこれらの機能を簡単にデプロイできるようになってきてはいますが、そもそもおうちサーバに監視基盤を載せてしまうとまるごとダウンしたときには検知出来ません。外部サービスに監視を任せたいというのが正直なところです。ただ、ミニPCをサーバにせざるを得ないほどの貧民であるため、当然富豪的にSaaSを使うことは出来ません。
この記事ではいくつかのSaaSを簡単に検討し、最終的に選んだGrafana Cloudについての簡単な解説をしたいと思います。必須の要件は以下の3つです。
- メトリクスの可視化:最低1週間程度はサーバの状態を可視化ができる
- ログ:最低1週間程度はサーバのログを保存・検索できる
- アラート:メトリクスに基づく死活監視ができる
SaaS 比較検討
記載されている価格・機能は2023年9月ベースのものです。
Mackerel
元々はこのMackerelを使っていました。このブログの運営元であるはてな株式会社が提供している純国産のモニタリングSaaSです。ホストベースでの課金になりますが、無料枠があります。
- 1スタンダードホストあたり200のメトリクス。1日だけ表示可能。5ホストまで無料。
- ログの扱いは無し
- アラートは10個まで
機能的にもう少し欲しいというのが正直なところでした。今回はこの乗り換え先を検討していく形になります。
Datadog
モニタリングのSaaSとして古くからあり、業務でも触れているためその信頼性の高さや使い勝手はよく知っています。ただ無料枠は大きくなく、料金も高額であるため今回は見送りとしました。
- メトリクス
- 無料枠では5ホストまで、1日以内のデータが閲覧可能。
- 有料枠は18.75ドル/ホストで15ヶ月以内のデータが閲覧可能(Proプラン)。高い。
- ログ
- 無料枠無し。取り込みに0.13ドル/GB/month、保持に2.13ドル/100万ログイベント/month(15日間の保持期限の場合)の料金がかかる。
- アラート
- メトリクスに含まれている。無料枠には記載なし。Pro以上は無制限。
Elastic Cloud
Elasticsearchで有名なElastic社のSaaSです。以前はELKスタックと呼ばれていた、Elasticsearch、Logstash、Kibanaをベースとした基盤を提供しています。インスタンスの構成をユーザが選んでプロビジョニングするのが特徴で、ある程度小規模な環境を組めます。
構築した環境の構成に関わらず、基本的な機能はElastic Cloudのプランによります。最も安価なStandardでもサーバメトリクスの収集、ログの保存・検索、アラートは一通り揃っていそうでした*1。保存可能な容量などは構築した環境の構成に寄ります。
いくつか試して最も安い構成は以下でした(全通り試したわけではないのでもっと安価にできるかも)。
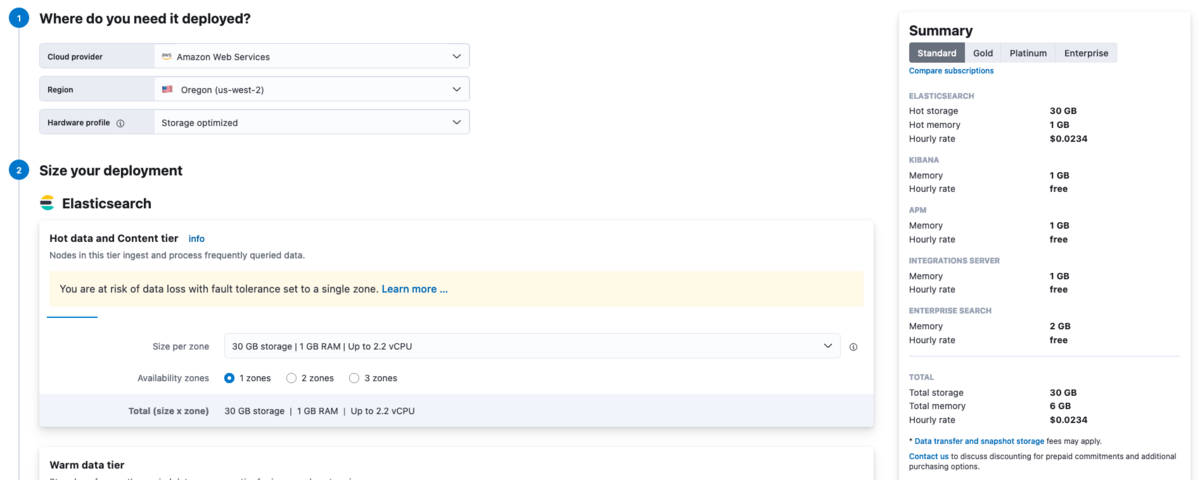
0.0234ドル/hourなので、月額に換算すると
$0.0234 * 24 hour * 30 days = $16.848
となり、およそ月額17ドルほどとなりました。30GBまでのログ・メトリクスが保存・検索できます。課金の単位がこのインスタンスに対するものなので、おうちサーバ台数が増えても料金は変わらないところはメリットです。
悪くはないですが、この構成では画像の警告にも出ているとおり容易にデータロスが発生する可能性があります。冗長度を持たせるために2 zoneにすると単純に料金2倍です。今回は見送りとしました。
NewRelic
これもオブザーバビリティ界隈では著名なSaaSの一つです。自社のアプリケーションにNewRelicのAPMが組み込まれているという方も多いのではないでしょうか。実は無料枠がそこそこ大きく、個人でも使いやすくなっています。
- データ送信100GiBまで無料。それを超えると0.3ドル/GB。
- データ保持期限は分かりづらいがデータによって異なる。少なくともどのデータも8日以上の保持期限がある。
- https://docs.newrelic.com/jp/docs/data-apis/manage-data/manage-data-retention/#find-ui
- 追加料金を払うことで保持期限は延ばすことが可能。
- フルアクセスユーザ1人まで無料。
いくつか制限がありますが、これらがどれくらい通常利用に影響してくるかまでは検討できていません。
今回APMの利用予定がなく、NewRelicの強みを活かせそうには思えなかったので見送りとしました。
Grafana Cloud
Grafana CloudはGrafanaが提供しているSaaSでGrafana製品が内部では利用されています。
- メトリクス
- 内部的にはMimir+Prometheusだと思われる。毎月1万種のメトリクスを送信可能。
- ダッシュボードによるビジュアライズが可能。3ユーザまで無料。
- ログ
- 内部的にはLokiだろうと思われる。毎月50GiBまで送信可能。
- 保持期限延長は追加料金
- アラート
- アラート・インシデント・オンコールのマネジメントが可能な仕組みが搭載。
他にもTempoによるトレーシング、k6による負荷試験の実施や、Grafana Pyroscopeを使ったパフォーマンスプロファイルの取得まで様々な機能があります。
様々なデータソースとの接続が可能ですが、基本的にはPrometheus+Lokiのマネージドサービスであると捉えています。実際にセットアップしていくとPrometheusやLokiのRemote Write用のURLが用意されており、そこに指定されたユーザ名と生成したAPIトークンで接続して書き込みます。そのため、必ずしも指定されたAgentを使わなければならないわけではなく、最終的にオンプレでPrometheusやLokiをホストすればスムーズに移行できるのも良いところだと思いました。
総合的に判断し、今回はGrafana Cloudを採用してみることにしました。
セットアップ
Grafana Cloudのアカウント作成
Grafana CloudのトップページからCreate free accountしてアカウントを作成します。
https://grafana.com/orgs/{{ 作成したorg名 }}/access-policies なURLにアクセスして、 -write で終わる書き込み可能なAccess Policyに対して Add Token してアクセストークンを発行します。名前は適当で良いです。
作成したトークンの文字列はメモっておく必要があります。
Grafana Agentのインストールとセットアップ
まずstaticモードとflowモードという2つのモードがあり、提供されるAgentのバイナリも両方違いますが、今回はstaticモードでデプロイします。理由はflowモードの説明が全く頭に入ってこなかったからです。
セットアップにはAnsibleを使っていますが、ほとんど生の設定を書くのとAnsibleのconfigを書くのに大きな違いは無いので適宜読み替えてください。また、Ansibleはインストール済み・対象サーバへの接続等はセットアップ済みであるとして進めます。
まず、Grafana関連のAnsible RoleはGrafanaが公式で公開しているのでこれをインストールします。
ansible-galaxy collection install grafana.grafana
これを使ってインストールするplaybookを書きます。人によってこの辺は色々やりかたがあると思うので、あくまでこれは一例と考えて下さい。
main.yaml:
--- - name: Install Grafana Agent hosts: all become: true tasks: - name: Install Grafana Agent ansible.builtin.include_role: name: grafana_agent # grafana_agent roleは変更後のconfigで正しく立ち上がっていることをチェックしない # REST APIを叩いてチェックする - name: Ensure that the grafana-agent is ready uri: url: http://localhost:12345/-/ready method: GET status_code: 200 # 成功するまで1秒間隔で5回までリトライする register: check_grafana_agent_readiness until: check_grafana_agent_readiness is not failed retries: 5 delay: 1
inventory fileなりhost_varsなりgroup_varsなりにconfigの変数を書きます。prometheusやLokiのUser、URLはStackの設定から見ることができます。 `https://grafana.com/orgs/{{ 作成したorg名 }}` のページからそれぞれのサービスの詳細に飛ぶことで設定を見ることができます。
group_vars/all.yaml:
--- # この値は実際にはansible-vaultで暗号化しておいた方が良い grafana_cloud_api_key: 'メモしておいたアクセストークン' # Prometheusのremote writeのBASIC認証に使うユーザ名(人によって違う) grafana_cloud_prometheus_user: '999999' # Prometheusのremote write URL(人によって違う) grafana_cloud_prometheus_url: 'https://prometheus-prod-XX-prod-YYYY.grafana.net/api/prom/push' # Lokiへのpush時のBASIC認証に使うユーザ名(人によって違う) grafana_cloud_loki_user: '999999' # Lokiのpush先URL(人によって違う) grafana_cloud_loki_url: 'https://logs-prod-ZZZ.grafana.net/loki/api/v1/push' # grafana-agentユーザがLinuxサーバ上に作られるが、 # 所属するグループはここで宣言しなければ全てパージされる grafana_agent_user_groups: # For journal logs - adm - systemd-journal # For container logs - docker grafana_agent_metrics_config: configs: - name: integrations remote_write: - basic_auth: password: '{{ grafana_cloud_api_key }}' username: '{{ grafana_cloud_prometheus_user }}' url: '{{ grafana_cloud_prometheus_url }}' global: scrape_interval: 60s wal_directory: /tmp/grafana-agent-wal grafana_agent_logs_config: configs: - name: default clients: - basic_auth: password: '{{ grafana_cloud_api_key }}' username: '{{ grafana_cloud_loki_user }}' url: '{{ grafana_cloud_loki_url }}' positions: filename: /tmp/positions.yaml target_config: sync_period: 10s scrape_configs: # 単一のファイルを指定して送信する例 - job_name: authlog static_configs: - targets: - localhost labels: instance: '${HOSTNAME:-default}' __path__: /var/log/auth.log job: auth.log # systemd-journalのログを送信する例 - job_name: integrations/node_exporter_journal_scrape journal: # 過去のログをどれくらい遡って送信するか max_age: 1h labels: job: systemd-journal instance: '${HOSTNAME:-default}' relabel_configs: - source_labels: ['__journal__systemd_unit'] target_label: 'service' - source_labels: ['__journal_priority_keyword'] target_label: 'level' # 余計なログ転送を抑えるためにsessionやuserなどのjournalログを送らず捨てる - source_labels: [__journal__systemd_unit] regex: ^session-\d+.scope$ action: drop - source_labels: [__journal__systemd_unit] regex: ^user@\d+.service$ action: drop # Dockerコンテナのログを自動的に見つけて送信する例。大量のコンテナがある場合には注意。 # また、長く運用しているコンテナがあり過去のログが残っている場合、先に削除しておくこと。 - job_name: integrations/docker docker_sd_configs: - host: unix:///var/run/docker.sock refresh_interval: 10s relabel_configs: - action: replace replacement: integrations/docker target_label: job - action: replace replacement: ${HOSTNAME:-default} target_label: instance - source_labels: - __meta_docker_container_name regex: '/(.*)' target_label: service - source_labels: - __meta_docker_container_log_stream target_label: stream grafana_agent_integrations_config: # node-exporterを起動してそのホストのメトリクスを取る node_exporter: enabled: true instance: ${HOSTNAME:-default} # disable unused collectors disable_collectors: - ipvs - btrfs - infiniband - xfs - zfs - nfs # エラーログが出るので無効にした - thermal_zone # exclude dynamic interfaces netclass_ignored_devices: "^(veth.*|cali.*|[a-f0-9]{15})$" netdev_device_exclude: "^(veth.*|cali.*|[a-f0-9]{15})$" # disable tmpfs filesystem_fs_types_exclude: "^(autofs|binfmt_misc|bpf|cgroup2?|configfs|debugfs|devpts|devtmpfs|tmpfs|fusectl|hugetlbfs|iso9660|mqueue|nsfs|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|selinuxfs|squashfs|sysfs|tracefs)$" # drop extensive scrape statistics relabel_configs: - replacement: ${HOSTNAME:-default} target_label: instance metric_relabel_configs: - action: drop regex: node_scrape_collector_.+ source_labels: - __name__ # デフォルトでは無駄に多いのでメトリクスを削る。もっと削っても良いかも。 - action: keep regex: node_time_seconds|node_arp_entries|node_boot_time_seconds|node_cpu_seconds_total|node_disk_io_time_seconds_total|node_disk_io_time_weighted_seconds_total|node_disk_read_bytes_total|node_disk_read_time_seconds_total|node_disk_reads_completed_total|node_disk_write_time_seconds_total|node_disk_writes_completed_total|node_disk_written_bytes_total|node_filefd_allocated|node_filefd_maximum|node_filesystem_avail_bytes|node_filesystem_device_error|node_filesystem_files_free|node_filesystem_readonly|node_filesystem_size_bytes|node_load1|node_load15|node_load5|node_md_disks|node_md_disks_required|node_memory_Active_anon_bytes|node_memory_Active_bytes|node_memory_Active_file_bytes|node_memory_AnonHugePages_bytes|node_memory_AnonPages_bytes|node_memory_Bounce_bytes|node_memory_Buffers_bytes|node_memory_Cached_bytes|node_memory_CommitLimit_bytes|node_memory_Committed_AS_bytes|node_memory_Dirty_bytes|node_memory_Inactive_anon_bytes|node_memory_Inactive_bytes|node_memory_Inactive_file_bytes|node_memory_Mapped_bytes|node_memory_MemAvailable_bytes|node_memory_MemFree_bytes|node_memory_MemTotal_bytes|node_memory_SReclaimable_bytes|node_memory_SUnreclaim_bytes|node_memory_ShmemHugePages_bytes|node_memory_ShmemPmdMapped_bytes|node_memory_Shmem_bytes|node_memory_Slab_bytes|node_memory_SwapTotal_bytes|node_memory_VmallocChunk_bytes|node_memory_VmallocTotal_bytes|node_memory_VmallocUsed_bytes|node_memory_WritebackTmp_bytes|node_memory_Writeback_bytes|node_netstat_Icmp6_InErrors|node_netstat_Icmp6_InMsgs|node_netstat_Icmp6_OutMsgs|node_netstat_Icmp_InErrors|node_netstat_Icmp_InMsgs|node_netstat_Icmp_OutMsgs|node_netstat_IpExt_InOctets|node_netstat_IpExt_OutOctets|node_netstat_TcpExt_ListenDrops|node_netstat_TcpExt_ListenOverflows|node_netstat_TcpExt_TCPSynRetrans|node_netstat_Tcp_InErrs|node_netstat_Tcp_InSegs|node_netstat_Tcp_OutRsts|node_netstat_Tcp_OutSegs|node_netstat_Tcp_RetransSegs|node_netstat_Udp6_InDatagrams|node_netstat_Udp6_InErrors|node_netstat_Udp6_NoPorts|node_netstat_Udp6_OutDatagrams|node_netstat_Udp6_RcvbufErrors|node_netstat_Udp6_SndbufErrors|node_netstat_UdpLite_InErrors|node_netstat_Udp_InDatagrams|node_netstat_Udp_InErrors|node_netstat_Udp_NoPorts|node_netstat_Udp_OutDatagrams|node_netstat_Udp_RcvbufErrors|node_netstat_Udp_SndbufErrors|node_network_carrier|node_network_info|node_network_mtu_bytes|node_network_receive_bytes_total|node_network_receive_compressed_total|node_network_receive_drop_total|node_network_receive_errs_total|node_network_receive_fifo_total|node_network_receive_multicast_total|node_network_receive_packets_total|node_network_speed_bytes|node_network_transmit_bytes_total|node_network_transmit_compressed_total|node_network_transmit_drop_total|node_network_transmit_errs_total|node_network_transmit_fifo_total|node_network_transmit_multicast_total|node_network_transmit_packets_total|node_network_transmit_queue_length|node_network_up|node_nf_conntrack_entries|node_nf_conntrack_entries_limit|node_os_info|node_sockstat_FRAG6_inuse|node_sockstat_FRAG_inuse|node_sockstat_RAW6_inuse|node_sockstat_RAW_inuse|node_sockstat_TCP6_inuse|node_sockstat_TCP_alloc|node_sockstat_TCP_inuse|node_sockstat_TCP_mem|node_sockstat_TCP_mem_bytes|node_sockstat_TCP_orphan|node_sockstat_TCP_tw|node_sockstat_UDP6_inuse|node_sockstat_UDPLITE6_inuse|node_sockstat_UDPLITE_inuse|node_sockstat_UDP_inuse|node_sockstat_UDP_mem|node_sockstat_UDP_mem_bytes|node_sockstat_sockets_used|node_systemd_unit_state|node_textfile_scrape_error|node_uname_info|node_vmstat_oom_kill|node_vmstat_pgfault|node_vmstat_pgmajfault|node_vmstat_pgpgin|node_vmstat_pgpgout|node_vmstat_pswpin|node_vmstat_pswpout|process_max_fds|process_open_fds source_labels: - __name__ prometheus_remote_write: - basic_auth: password: '{{ grafana_cloud_api_key }}' username: '{{ grafana_cloud_prometheus_user }}' url: '{{ grafana_cloud_prometheus_url }}' grafana_agent_env_vars: HOSTNAME: '%H'
この設定をデプロイします。
# -K を付けるとSSH先で使うパスワードを実行時に聞かれる ansible-playbook -K main.yaml
コケずに走りきったらセットアップ終了です。
cAdvisorを建てる
grafana-agentにはcAdvisorを内部で起動する機能がありますが、この方法で建てたgrafana-agentでは、cAdvisorもgrafana-agentユーザで起動してしまいます。すると /var/lib/docker 以下などへのアクセスでエラーが出まくるので嬉しくありません。cAdvisorだけroot権限を付与して別に起動します。詳細は↓を参照。
これもAnsibleで建てても良いでしょう。
cAdvisorのメトリクスを参照する
先ほど適用した設定にcAdvisorのメトリクスを取りに行く設定を入れます。
grafana_agent_metrics_config: configs: # ... 省略 ... - name: cadvisor scrape_configs: - job_name: cadvisor static_configs: # リモートホスト上でcAdvisorがリッスンしているアドレスを指定する - targets: ['localhost:8080'] labels: instance: '${HOSTNAME:-default}' relabel_configs: - source_labels: ['name'] target_label: 'service' # デフォルトでは多すぎるので適当にメトリックを削る metric_relabel_configs: - action: keep regex: container_cpu_usage_seconds_total|container_fs_inodes_free|container_fs_inodes_total|container_fs_limit_bytes|container_fs_usage_bytes|container_last_seen|container_memory_usage_bytes|container_network_receive_bytes_total|container_network_tcp_usage_total|container_network_transmit_bytes_total|container_spec_memory_reservation_limit_bytes|machine_memory_bytes|machine_scrape_error source_labels: - __name__ remote_write: - basic_auth: password: '{{ grafana_cloud_api_key }}' username: '{{ grafana_cloud_prometheus_user }}' url: '{{ grafana_cloud_prometheus_url }}'
これを再び適用して走りきればOK。
Grafana Cloudで表示する
ダッシュボードを作る
最初はNode Exporterで取得したメトリクスをまずは表示してみます。
GrafanaでPrometheusをdatasourceとしたときのダッシュボードの作り方は他に無限に情報があるのでここでは詳しく解説しません。今回は既に公開されているものをimportして利用します。
https://grafana.com/grafana/dashboards/1860-node-exporter-full/
https://{{ 作成したorg名 }}.grafana.net/ にアクセスし、右上の + から import dashboardを開くと上記のリンクのダッシュボードをimportできるUIが出てくるので適当にimportします。

こんな感じで見えるダッシュボードが生成されればOK。
色々設定すると、自前でもこんな感じのダッシュボードが作れます。

ログを検索する
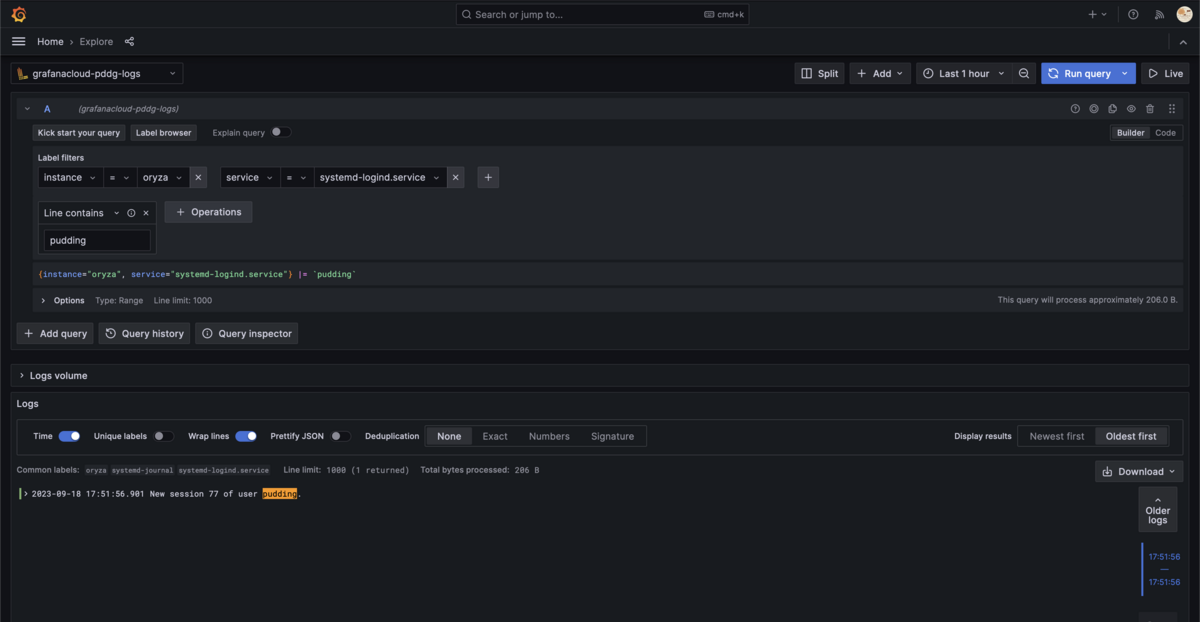
ログをダッシュボードに表示する方法なども他の記事に譲るとして、アドホックにログを検索するやり方だけ書いておきます。ハンバーガーメニューから Explore をクリックするとログやメトリクスを指定して表示する機能が出てきます。データソースを grafanacloud-{{ 作成したorg名 }}-logs にして適用な検索内容を入れると表示されることが分かります。
無料枠を超えないために
Grafana Cloudにはハードリミットを用意してそれを超えたら一切受け付けないようにして課金されないようにするような仕組みはありません。そのため、予期しないログのバーストなどで課金されないようにするにはユーザが頑張るしかないようです。
Promtailの設定にリミットを入れる
一行当たりのサイズや送信レートにリミットをかけ、そもそも大量に送られないようにします。
より詳細に、例えば特定のログストリームだけ異なる設定を適用する場合はpipelineを使います。
scraping intervalを広めにとる
細かくメトリクスが欲しくなってしまいますが、DPMという概念があるため1分より早い頻度でのデータの送信は無料枠のアカウントには含まれていません。Grafana Agentなどのデフォルトは60sになっているので、これ以上縮めないようにしましょう。
grafana_agent_metrics_config: configs: # ... 省略 ... global: scrape_interval: 60s
不要なメトリクスやlabelをdropする
見ることがないメトリクスは取っていても意味が無いため、そもそも送らないようにします。また、不要なlabelについてもdropすることでbillable seriesを減らせます。
drop や labeldrop を使って不要なメトリック・ラベルはどんどん削っておくとサーバ台数が増えても無料枠に収まるはずです。
アラートを仕掛ける
まずは無料枠の上限に近づいてきたらアラートを出すようにします。
公式のドキュメントにメトリクスの課金アラートに関する設定例が載っていますが、これは課金する前提の場合であり、実際に課金されるような使用量に至るまで検知出来ません。
監視するだけならそれほど必要ではないのですが、各リソースの利用量の計算の仕方と、無料枠で許されている範囲を把握しておいた方がよいです。今回はログとメトリクスに関してだけ考えますが、他のリソースでもドキュメントに計算方法は書いていますのでそれを参考にして下さい。
https://grafana.com/docs/grafana-cloud/account-management/billing-and-usage/active-series-and-dpm/
https://grafana.com/docs/grafana-cloud/account-management/billing-and-usage/logs-billing/
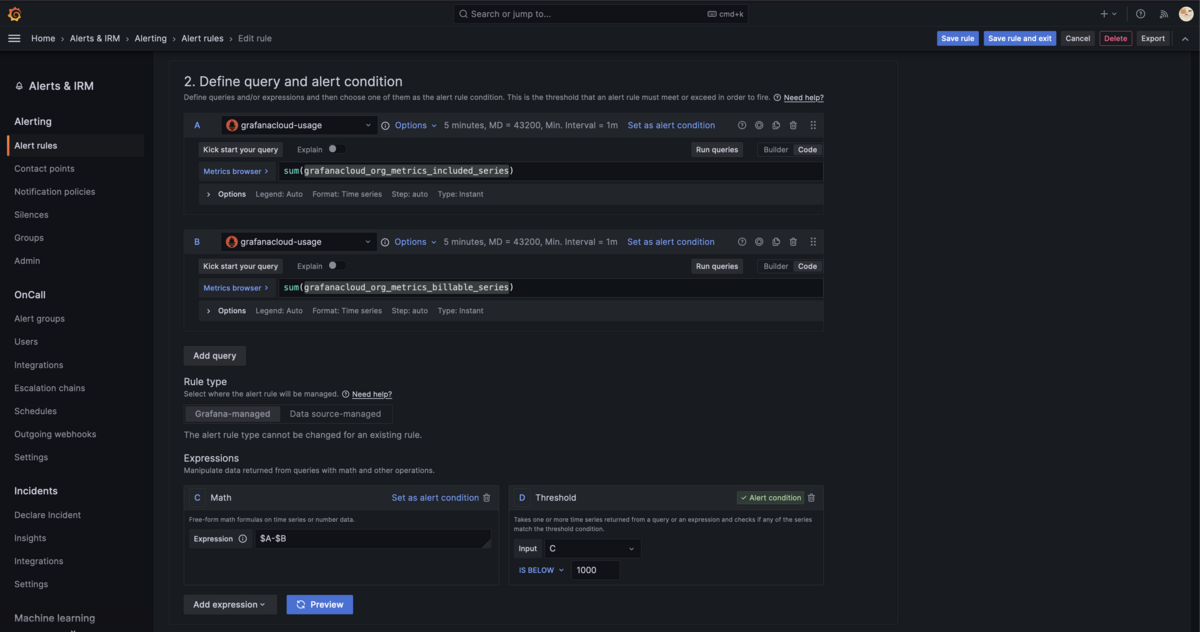
Metricであれば grafanacloud_org_metrics_billable_series という、課金対象となるmetricsのseriesを表すメトリックが現在いくつかなのかを監視します。ただし、ユーザには最初の10k seriesまで無料という無料枠( grafanacloud_org_metrics_included_series というメトリックで取得できる )が用意されているので、これにどれくらい近接したかを監視します。
Logでもほぼ同様で、 grafanacloud_org_logs_usage というメトリックを監視します。このメトリックの単位はGBです。 grafanacloud_org_logs_included_usage に無料枠の上限(50GB。無料トライアルの間は100GB)が入っているので、その差分がいくつになったらアラートを鳴らすかを記述します。
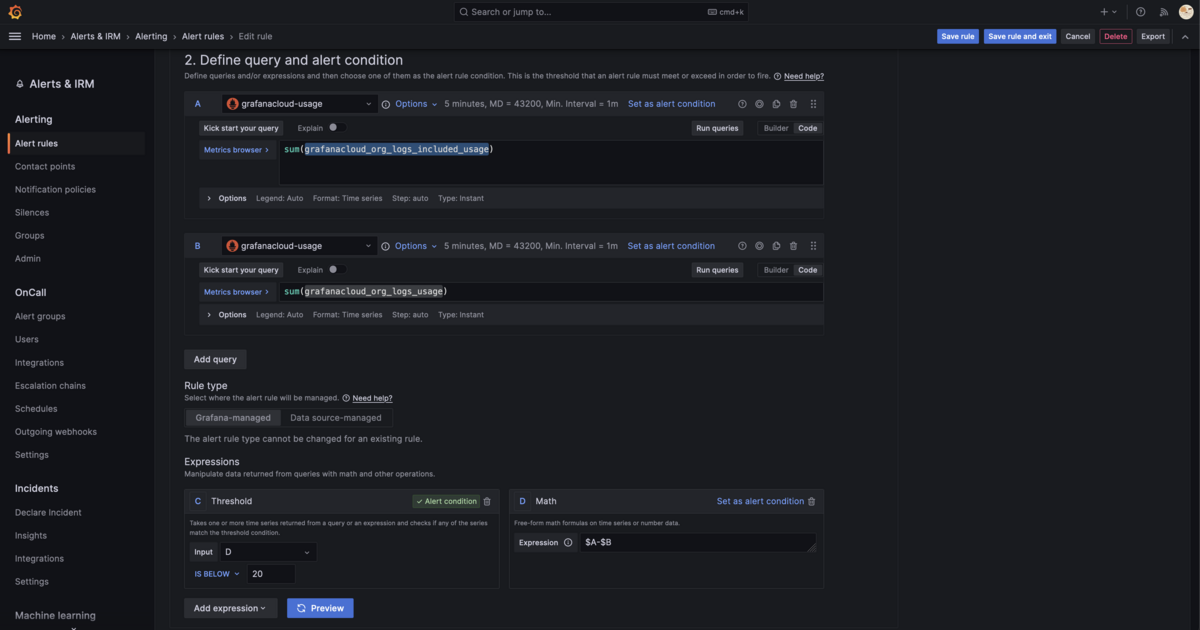
また、 grafanacloud_org_logs_overage というメトリックに現在の超過料金が入っているのでこれが0以上になったらという監視を入れたり、ログの流量 grafanacloud_logs_instance_bytes_received_per_second が一定以上の状態が30分以上続いたら、などの条件でアラートを入れ最終的に自分の環境では以下の様になりました(伝わらない)。
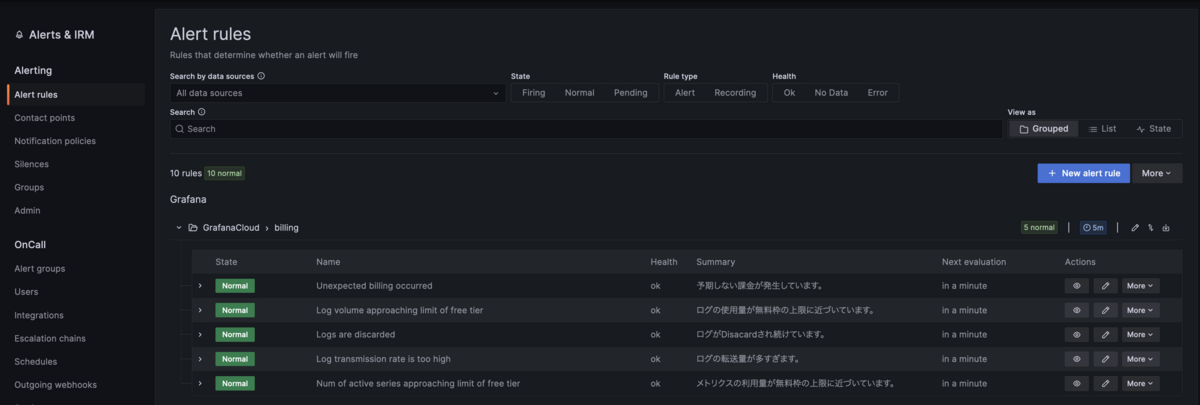
サポートからはGrafana Machine Learningなどを活用して異常検知するなども提案されましたが、Free accountにはMachine Learningは含まれていないので今のところ検討していません。
2023-09-23 追記 grafanacloud-usage datasourceが1日に1回くらいの割合でNoDataになってアラートを飛ばしてくるので、NoDataになったときの挙動をOKにしてしまうのがおすすめです。どうせNoDataになってもユーザ側で対応できることは何もないので、それで十分だと思います。
注意点
Grafana Cloudのログの無料枠とは保存容量ではなく、送信量に対してかかります。そのため、何らかの理由でGrafana Cloudのサーバ側からリジェクトされた場合でもその容量は課金対象です。例えばログのタイムスタンプがある程度以上古かったり未来を指している場合にエラーになることがあり、実際には拒否されているにもかかわらずBillable Usageだけは増加することがあります。
これについてはもう少し詳しく別記事で解説できればと思っています。
まとめ
- Grafana と Prometheus、Lokiのマネージドサービスという感じで使い慣れている人には色々使い勝手が良い
- ただしあまり親切とは言い難いので、料金を抑えるために使う側で色々な工夫が必要
- ちょっとした自宅サーバのログやメトリックを保存しておく分には十分な無料枠
- 無料枠に感謝し、色々触ってみて業務に活かしていきたい
*1:あまりにも機能比較のチェックリストが長い https://www.elastic.co/jp/subscriptions/cloud