ISUCON優勝したくてGrafana Cloudで分析基盤を整えた
去年のnonyleneくんのブログを読んだ僕の、一年越しの回答です。
ISUCON13に参加し、最高107000点くらい106457点をマークしましたがfailしたチーム ツナ缶です。来年は優勝します。
公式から全チームのスコアおよび結果が出ました。failしていなければ最低でも16位くらいだったと思われ、大変無念です。 ISUCON13 受賞チームおよび全チームスコア : ISUCON公式Blog
今回は割とよい分析基盤が出来たかなと思ったので紹介します。
メンバー紹介:
Grafana Cloudとは
詳しくは↓を参照
2ヶ月ほど前に家の監視基盤をGrafana Cloudに移したのは、ISUCONに向けた素振りをするためでもありました。Grafana Cloudで基盤を作ると良さそうと感じたのは主に以下の点でした。
- ログの閲覧ができる
- ログをパースしてメトリクスとして集計して可視化できる
- メトリクスを送信することでサーバの負荷状況を同じプラットフォームで可視化できる
- Goのpprofに対応した継続的プロファイリングにより、フレームグラフを同じプラットフォームで閲覧できる
- 上記を全て単一のAgentでアプリにほとんど手を入れずに実現できる←ここ重要
他にも仕事でGrafanaやPrometheus、Lokiとは仲良くしているので、これらを使った解析基盤は自分の知見が活かせるのでは(そして仕事でも使えるのでは)という思惑がありました。
できたもの
APIエンドポイントごとの解析

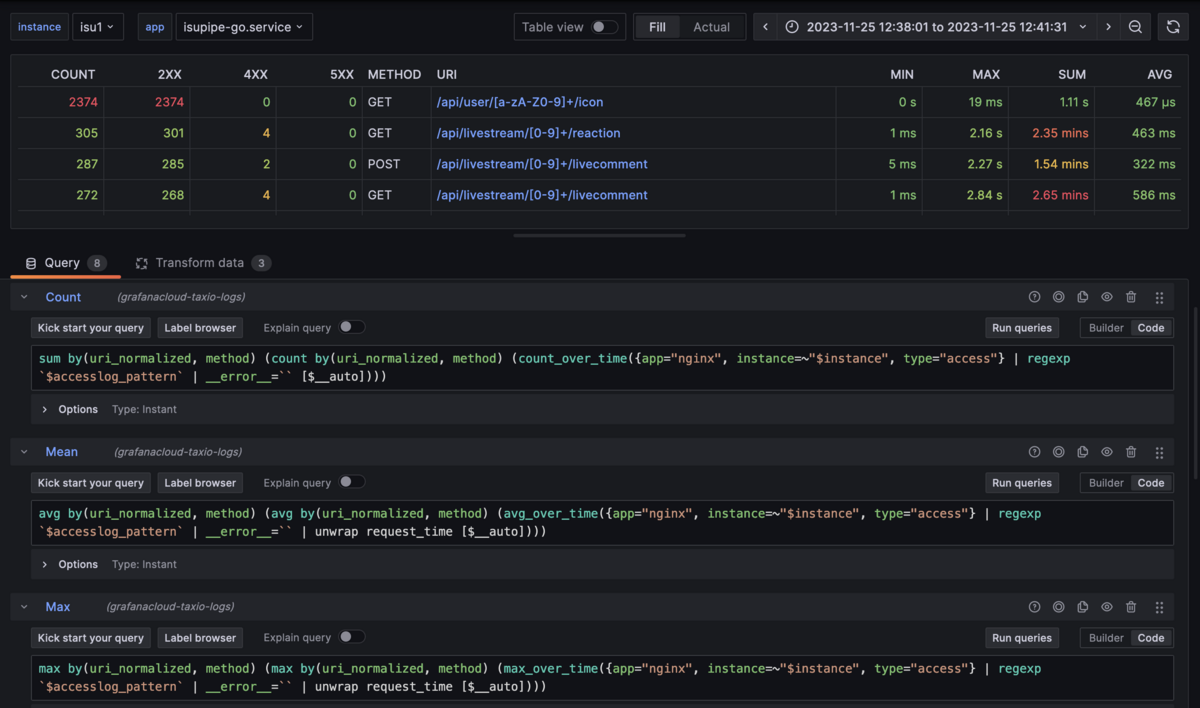
alp相当の解析ができるダッシュボードです。nginxのアクセスログをパースしてAPIエンドポイント・メソッド・レスポンスタイムの情報を頑張って組み立てています。各テーブルヘッダをクリックすることでインタラクティブにソートできるので、見たい人が見たい順に並べ直すことができます。
各URIはリンクになっており、各エンドポイントごとの詳細を別ダッシュボードで閲覧できるようになっています。

これらは全てグラフや右上の日時指定ボタンから指定日時のデータを見ることができるため、何時頃の結果、などを解析することも可能です*1
ログの閲覧・検索

時間範囲を指定して、アプリケーションやnginxのログを一つの画面で横断検索できるようにしました。ページ上部のドロップダウンメニューから見るインスタンス(全てまとめてみることも可)を、検索ボックスに任意文字列を入れて絞り込みなどができるようになっています。これらは自分はベンチマークのfail時などによく確認していました。
またエンドポイントごとの詳細画面では、エンドポイントの正規表現を使ってログをフィルタし、特定のエンドポイントのアクセスログだけを引っ張って来るなどもしていました。

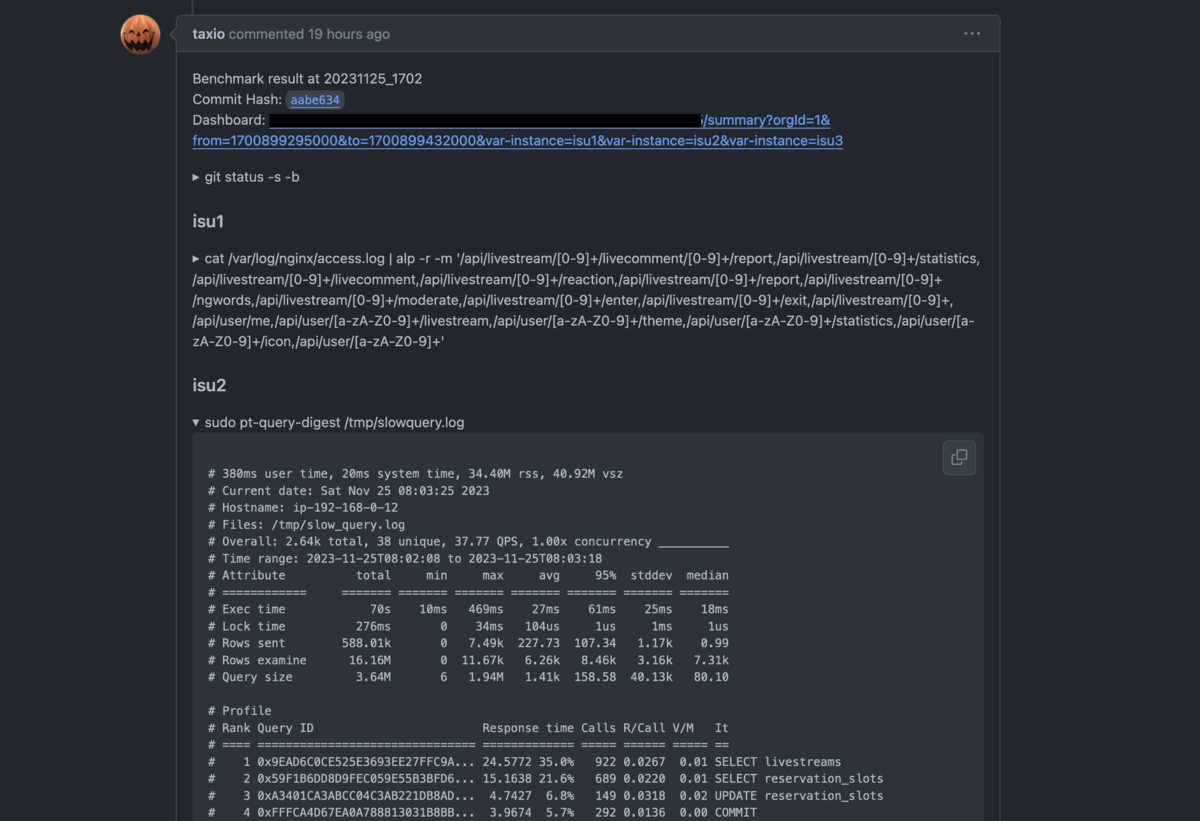
MySQLでスロークエリログを有効化した場合、それも収集するようにしていました。これの数はかなり膨大で結構大変な事になっていたと思います。

指定した時間範囲で指定した秒数以上かかったクエリを表示することができます*2。ロック時間などで並び替えることも出来るようになっています。
インスタンスの負荷状況の可視化
各インスタンスではNode Exporterが動作しており*3、各ホストの状況のメトリクスを送っていました。今回は15秒に一回送信することにしていましたが、もう少し解像度が高い方がISUCONという競技では使いやすかったなと思います。

フレームグラフの表示
Grafana LabsがPyroscopeを買収したことにより実現した機能です。Grafana Agentが定期的に /debug/pprof/profile などを叩くことで、Grafana Cloudへこれらのプロファイリングデータを送信して可視化しています。

各関数にフォーカスして拡大することもでき、検索ボックスから特定の関数を調べることも可能です。go tool pprof を使って閲覧するのと変わらないような使い勝手で、しかもこちらが実施することは最初のGrafana Agentのセットアップと、Goアプリケーションでのpprof対応だけでした。セットアップはAnsibleで自動化済み、pprof対応はlabstack/echoでは依存足して1行書き足すだけだったので、ほぼ労力ゼロでこれが使えるのはかなり良いと思いました。
ログ・メトリクス・プロファイルが全て単一のプラットフォームで見れるため、他のツールの使い方を覚えたりログインを使い分ける必要がありません。また、当日に追加で行った変更は以下のような、Grafana Cloudを用いなくてもやっているいつものことだけです。
これらの対応を全て終えてISUCON本番で完全に動作し始め、ベンチマーク結果を解析出来るようになったのはおおよそ競技開始から40分後くらいでした。その間もtaxioにはマニュアルの読み込みやUIを触って理解を深めてもらうなどをやってもらっており、初動としてはそこまで悪くないかなと思っています。
さらに、そこから先で解析基盤に手を入れることはほとんどありませんでした。撤退も単にGrafana Agentを消す、pprof対応を消す、ログを出さないようにするだけで良いので非常に簡単でした。
構築編
Grafana CloudはSaaSなので、自分でセルフホストする必要がありません。収集対象のインスタンスにエージェントを入れるだけで使えます。
Grafana Agent Flowのインストール
Grafana Cloudへのログやメトリクス、プロファイルデータの送信にはGrafana Agentというエージェントを利用します。これはstatic mode(YAMLで設定を書ける)とflow mode(HCLみたいなriverという設定言語で書ける)の2種類のモードがありますが、プロファイルデータを送れるのがflow modeだけなので今回はflow modeを使います。
GitHub Releasesでdebパッケージが公開されているので単にこれをダウンロードしてきて各ホストに入れます。自分はAnsibleで全ホストにサクッと入れられるようにしておきました。
また、送信に必要なのでGrafana CloudのAPIキーを各ホストに撒いておきます。適当なところにファイルに書いて置いておきました。Grafana CloudではAPIキーのExpire dateを設定できるので、翌日とかにしておくと安心です。
メトリクスを収集する
flow modeではriverで設定ファイルを書くのですが、これはモジュール化出来るようになっています。今回は以下の様なモジュールを書いていました。
// このモジュールが取る引数を宣言できる。 argument "write_to" { comment = "remote write target" } // Node Exporterの設定をする prometheus.exporter.unix "default" { include_exporter_metrics = false // ISUCONではそこまで細かいメトリクスは要らないので適当に set_collectors = [ "cpu", "diskstats", "filefd", "filesystem", "loadavg", "meminfo", "netclass", "netdev", "vmstat", "sockstat", ] filesystem { fs_types_exclude = "^(autofs|binfmt_misc|bpf|cgroup2?|configfs|debugfs|devpts|devtmpfs|tmpfs|fusectl|hugetlbfs|iso9660|mqueue|nsfs|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|selinuxfs|squashfs|sysfs|tracefs)$" } netclass { ignored_devices = "^(veth.*|cali.*|[a-f0-9]{15})$" } netdev { device_exclude = "^(veth.*|cali.*|[a-f0-9]{15})$" } } // 設定したNode Exporterからメトリクスをスクレイプする設定 prometheus.scrape "unix" { targets = prometheus.exporter.unix.default.targets // このモジュールの引数で渡された書き込み先に渡す forward_to = [argument.write_to.value] scrape_interval = "15s" }
このモジュールを使う側では、以下の様に宣言するだけです。
// Grafana CloudのAPI Keyを書いておくファイル local.file "api_key" { filename = "/etc/grafana-agent-api-key" is_secret = true } // Grafana Cloudの書き込み先の設定 prometheus.remote_write "grafanacloud" { endpoint { url = "REMOTE WRITE URL" basic_auth { username = "BASIC AUTH USER" password = local.file.api_key.content } } } // ラベルを書き換える prometheus.relabel "replace_instance" { forward_to = [prometheus.remote_write.grafanacloud.receiver] rule { action = "replace" target_label = "instance" // Ansibleでここを各ホストごとの識別名に置き換えていた replacement = "{{ inventory_hostname }}" } } module.file "nodeexporter" { // 先ほどのモジュールまでのファイルパス filename = "/etc/grafana-agent/rivers/nodeexporter.river" arguments { write_to = prometheus.relabel.replace_instance.receiver } }
ログを収集する
ISUCONではログの収集パターンは主に2つだと考えていました。
- journaldのログ(
journalctl -u ~~などで見る物) - ローカルにあるファイルに書かれるログ
Grafana Agentではどちらも対応可能です。まずはjournal logの収集から。
argument "write_to" { comment = "Loki remote write url" } loki.relabel "journallog" { // forward_toはloki.source.journal側で指定するので記述しない forward_to = [] // 書き換えのルールの指定。 // `__` から始まるラベルは送信時にドロップされるので必要なものを抽出する。 rule { source_labels = ["__journal__systemd_unit"] target_label = "app" } rule { source_labels = ["__journal_priority_keyword"] target_label = "level" } } // Journaldをソースとしてログを収集する loki.source.journal "journallog" { forward_to = [argument.write_to.value] // 最大どれくらい前のログまで収集するか。過去のログは要らないので回収しない。 max_age = "10m" // ラベルの書き換え設定 relabel_rules = loki.relabel.journallog.rules // 静的に設定するラベルの指定 labels = { job = "loki.source.journal", } }
このモジュールを使ってGrafana Cloudに送信する設定は以下
// Grafana Cloudのログのリモート書き込み先の設定 loki.write "grafanacloud" { endpoint { url = "REMOTE WRITE URL" basic_auth { username = "BASIC AUTH USER" password = local.file.api_key.content } } } // Grafana Cloudのハードリミットに引っかからないよう、大きすぎる/古すぎるログを落とす // Ref: https://grafana.com/docs/grafana-cloud/cost-management-and-billing/understand-your-invoice/usage-limits/#logs-usage-limits loki.process "drop_abnormals" { forward_to = [loki.write.grafanacloud.receiver] stage.drop { longer_than = "255KB" drop_counter_reason = "too long" } stage.drop { older_than = "1h" drop_counter_reason = "too old" } } // メトリクスと同様にinstance名にホストの識別子を入れる loki.relabel "replace_instance" { forward_to = [loki.process.drop_abnormals.receiver] rule { action = "replace" target_label = "instance" replacement = "{{ inventory_hostname }}" } } // 今回はisupipe-goのログがあれば良かったのでこう書いていますが、 // regexを工夫することでpdns.serviceのログも収集できます。 loki.relabel "filter_app" { forward_to = [loki.relabel.replace_instance.receiver] rule { source_labels = ["app"] regex = "^isupipe-go.*$" action = "keep" } } module.file "journallog" { // 先ほどのモジュールまでのファイルパス filename = "/etc/grafana-agent/rivers/journallog.river" arguments { write_to = loki.relabel.filter_app.receiver } }
次にファイルからのログを収集します。単純なログであれば以下の様に書けば収集できます。
argument "write_to" { comment = "Loki remote write target" } // ラベル足したり要らないラベル落としたりとか loki.process "error" { forward_to = [argument.write_to.value] stage.static_labels { values = { app = "mysql", type = "error", } } stage.label_drop { values = ["filename"] } } // MySQLのエラーログを探索させ、存在する場合ターゲットに加える local.file_match "errorlog" { path_targets = [{"__path__" = "/var/log/mysql/error.log.*"}] } // 発見されたエラーログをソースとしてログを送信する loki.source.file "error" { targets = local.file_match.errorlog.targets forward_to = [loki.process.error.receiver] // 過去のデータは要らないので、起動時は常に末尾から読み取っていく。 tail_from_end = true }
先述したようにriverでは様々なモジュール同士の接続を自由に書けるので、このモジュールとjournallogモジュールはログの処理フェーズを共有できます。
module.file "mysql_error_log" { filename = "/etc/grafana-agent/rivers/mysql_error_log.river" arguments { // ラベルの書き換え設定から繋げることで、そこから先を共通化できる write_to = loki.relabel.replace_instance.receiver } }
アクセスログの収集
nginxのアクセスログを元にダッシュボードを表示したいのですが、通常はパスにパラメータなどが入っており統計処理に向いていません。同様のことにnonyleneくんも気付いており、収集時に正規化するという方法を取っていました。
Grafana Agentにおいても同様の処理を行います。前提としてnginxのログ形式は以下の様になっているとします。
log_format main "time:$time_local"
"\thost:$remote_addr"
"\tforwardedfor:$http_x_forwarded_for"
"\treq:$request"
"\tstatus:$status"
"\tmethod:$request_method"
"\turi:$request_uri"
"\tsize:$body_bytes_sent"
"\treferer:$http_referer"
"\tua:$http_user_agent"
"\treqtime:$request_time"
"\tcache:$upstream_http_x_cache"
"\truntime:$upstream_http_x_runtime"
"\tapptime:$upstream_response_time"
"\tvhost:$host"
"\trequest_id:$request_id";
access_log /var/log/nginx/access.log main;
まずは前処理としてnginxのログをパースします。
// nginxのアクセスログをパースして各パラメータをラベルに加える loki.process "access" { // 後段の処理を指定 forward_to = [loki.relabel.access.receiver] stage.static_labels { values = { app = "nginx", type = "access", } } stage.label_drop { values = ["filename"] } // LTSV形式のログ行をパースする。正規表現でバックスラッシュを使いたい時は2つ重ねる。 // 後から気付いたけどこれはjsonにしておけばもっと楽にパースできたので、 // 皆さんはこれをパクらずにnginxにjson形式でログを吐かせてください。 stage.regex { expression = "^time:(?P<time>.*)\\thost:(?P<host>.*)\\tforwardedfor:(?P<forwardedfor>.*)\\treq:(?P<request>.*)\\tstatus:(?P<status>.*)\\tmethod:(?P<method>.*)\\turi:(?P<uri>.*)\\tsize:(?P<body_bytes_sent>.*)\\treferer:(?P<http_referer>.*)\\tua:(?P<http_user_agent>.*)\\treqtime:(?P<request_time>.*)\\tcache:(?P<upstream_http_x_cache>.*)\\truntime:(?P<upstream_http_x_runtime>.*)\\tapptime:(?P<upstream_response_time>.*)\\tvhost:(?P<vhost>.*)\\trequest_id:(?P<request_id>.*)$" } // ログ行からアクセス日時をとりだしてログの記録日時とする stage.timestamp { source = "time" format = "02/Jan/2006:15:04:05 -0700" } // 正規化したいパラメータを抽出する stage.labels { values = { status_normalized = "status", uri_normalized = "uri", } } } local.file_match "accesslog" { path_targets = [{"__path__" = "/var/log/nginx/access.log.*"}] } loki.source.file "access" { targets = local.file_match.accesslog.targets forward_to = [loki.process.access.receiver] tail_from_end = true }
後は実際に本番で実装されているエンドポイントに合わせて設定ファイルを書いて正規化させるだけです。
loki.relabel "access" { forward_to = [argument.write_to.value] // alpが 2XX や 5XX のように表示するのが分かりやすかったので同じ事をする rule { source_labels = ["status_normalized"] regex = "^([0-9])[0-9]+$" replacement = "${1}XX" target_label = "status_normalized" } // クエリパラメータを消す rule { source_labels = ["uri_normalized"] regex = "^(.*)\\?(.+)$" replacement = "$1" target_label = "uri_normalized" } // 以下の様なルールをエンドポイントの数だけ書く。マッチするラベルだけが置き換えられる。 // 本番ではAnsibleでテンプレートを書いておいて自動生成した rule { source_labels = ["uri_normalized"] regex = "^/api/user/[a-zA-Z0-9]+$" replacement = "/api/user/[a-zA-Z0-9]+" target_label = "uri_normalized" } }
Grafanaのダッシュボードではこの送信されたログを再度同じ正規表現でパースし直してレスポンスタイムを取りだし、ラベルとして付与された uri_normalized などを元に行数をカウントしたり最悪レスポンス時間を取り出したりしています。
スロークエリログの収集
MySQLのスロークエリログは、一行ごとに結果が出るのではなく複数行にわたっています。こういったログも設定を書くことで収集できます。
loki.process "slowquery" { forward_to = [argument.write_to.value] stage.static_labels { values = { app = "mysql", type = "slowquery", } } stage.label_drop { values = ["filename"] } // この行から次のこの行までを一つのログとして扱う stage.multiline { firstline = "^#\\sTime:.*$" } // ログをパースする正規表現 stage.regex { expression = "#\\s*Time:\\s*(?P<timestamp>.*)\\n#\\s*User@Host:\\s*(?P<user>[^\\[]+).*@\\s*(?P<host>.*]).*Id:\\s*(?P<id>\\d+)\\n#\\s*Query_time:\\s*(?P<query_time>\\d+\\.\\d+)\\s*Lock_time:\\s*(?P<lock_time>\\d+\\.\\d+)\\s*Rows_sent:\\s*(?P<rows_sent>\\d+)\\s*Rows_examined:\\s*(?P<rows_examined>\\d+)\\n(?P<query>(?s:.*))$" } // 時間をパースしてそのログの時間として設定する stage.timestamp { source = "timestamp" format = "RFC3339Nano" } } local.file_match "slowquery" { path_targets = [{"__path__" = "/tmp/slow_query.log*"}] } loki.source.file "slowquery" { targets = local.file_match.slowquery.targets forward_to = [loki.process.slowquery.receiver] tail_from_end = true }
これは生データのみしか収集できないので、pt-query-digest等も組み合わせることを検討すべきかも知れません。自分たちのチームではpt-query-digestはそれは別途ベンチの度に走らせてリポジトリのIssueに結果を書いており、それで済ませていました。
プロファイルデータの取得
Goアプリケーション自体が /debug/pprof エンドポイントを実装していれば、Grafana Agentが書くことはたったこれだけです。実際にはインスタンス名やサービス名、アクセス先のポート番号などは全てAnsibleで動的に埋めています。
pyroscope.write "grafanacloud" { endpoint { url = "REMOTE WRITE URL" basic_auth { username = "BASIC AUTH USER" password = local.file.api_key.content } } } pyroscope.scrape "pprof" { targets = [ {"__address__" = "localhost:8080", "instance" = "{{ inventory_hostname }}", "service_name" = "isupipe"}, ] forward_to = [pyroscope.write.grafanacloud.receiver] scrape_interval = "15s" }
ハマったところ
何でもログのラベルに付与すると死ぬ
Grafana Cloudのログ収集機能には max_global_streams_per_user というハードリミットがかかっています。値は5000です。
これは送信するログに付与するラベルの値の組み合わせの数が相当します。つまり、インスタンスの数が5つあり、それぞれ3種類の値を取るラベルが2つあるとすると、5 × 2 × 3 = 30 のactive streamとなります。
当初、nginxのアクセスログをパースして全てラベルとして付与していましたが、練習の段階でGrafana Agentがこのリミットに引っかかったというエラーを吐いていました。当然です。レスポンスタイムの値、正規化していないURLのパスなどがそのまま入ると、あっという間に5000通りくらいの組み合わせに到達します。
一度に全ログが取得できるわけではない
GrafanaのダッシュボードではTransformという取得したメトリクスを加工する機能が存在しています。そこでGROUP BYしてカウントしたりも可能です。最初期のダッシュボードではLogQLを使ってnginxのアクセスログを全行取ってきてTransform機能でカウントしようとしていましたが、デフォルトでは1000行まで、最大でも5000行までしか一度に取得できず不完全な解析となってしまいました。
最終的には以下の様にLogQLでメトリクスを取ってきて、Transformは最低限になっています。

メトリクスのDPM
送信するログ量自体は競技時間全てを合わせても無料枠を超えませんが、メトリクスをどの頻度で取得するかによって課金額に影響するDPMというパラメータがあります。
これは Data points per minute の略で、Grafana Agentのscrape intervalのデフォルト60秒が1DPMです。これがGrafana Cloud FreeおよびProアカウントのデフォルトです。これを超えた場合、課金額に影響があります。ISUCONでは60秒ごとでは遅すぎるので、競技中のみ15秒に一回スクレイプするようにしました。おそらくこれくらいなら大丈夫ですが、長期間使うインスタンスでは辞めておくべきでしょう。
競技終盤はアクセス数が増えて解析が遅い
これは正規表現でアクセスログをパースしていたことによる可能性を拭えないのですが、競技終盤になるとエンドポイントごとの解析画面は結果の表示に数十秒かかるようになってしまいました。フレームグラフは見れるので、とりあえず開いてクエリを走らせている間にフレームグラフを見るといた感じにしていました。
一位のNaruseJunのチームだとおそらく中盤当たりで使い物にならなくなっていた可能性があります。とはいえほとんどのチームでは自分たちが捌いていたくらいのアクセス数に収まっていると思うので、十分実用的と言えるのではないでしょうか。
完全に同じログ行は重複排除で消える
今回前提としたnginxのログの形式は実はalpのREADMEに書かれているLTSV形式そのままではなく、末尾にrequest_idを追加しています。これはGrafana CloudというかおそらくそのバックエンドになっているLokiのQuerierの制約を回避するためです。
QuerierはLogQLを元に、データを問い合わせて返すコンポーネントです。
https://grafana.com/docs/loki/latest/get-started/components/#querier
the querier internally deduplicates data that has the same nanosecond timestamp, label set, and log message.
これには冗長化のために重複しているログを排除するという機能が実装されています。nginxのログのタイムスタンプの精度は秒単位のため、アクセス数の多いエンドポイントでは容易に全く同じログが吐かれてしまうことがあり、alpの結果とGrafanaダッシュボード上での結果が一致しないことが起きていました。
ログ行自体が完全に一致しなければ異なるログ行として扱われるため、request_id(リクエストごとに一意な値)を出力することで、重複排除によって消えないようにしています。
本番でやったこと・感想
自分が本番でやったことです。
- ~10:40:環境構築・解析基盤の準備
- ~12:00:icon画像をDBから剥がしてX-Accel-Redirectでnginxにサーブさせ、sha256のチェックサムをオンメモリにキャッシュ
- ~13:30:ミドルウェアのチューニングや、moderateHandlerの高速化
- ~15:30:DNS水責め対策に奮闘したが失敗
- ~17:00:DBのレプリケーションをしてリードレプリカを使うようにしたが整合性チェックが通らず失敗
- ~17:30:最終的な複数台構成にした。(nginx, app, pdns)、(DB for app)、(DB for DNS)という構成。
- ~18:00:全ての解析系を止めて再起動試験をし、キャッシュ実装がダメでfailすることに気付く
途中ベンチマークの不具合で大きな変更がちゃんと通るかどうかを検証できず、競技時間伸びないかなとちょっと期待していました。それは叶わず残念。
taxio、shanpuがあらゆるものをメモリに載せようと奮闘している間に自分はDNS水責めの対策をしていました。正直に言ってDNSの知見があまりに乏しく、PowerDNSの設定を変えてDBの向き先を変更してアプリのDBの負荷を減らすのが限界でした。しかし、これも最善手だったとは思っていません。DNSを正しく捌いてしまうことでむしろアプリの負荷が増えていた可能性があります。DNSサーバを自前実装する可能性を一瞬検討し、理解と実装に半日はかかると踏んでDNSを切り捨てる判断をしました。チャレンジすべきだったのかなぁと後悔はつきません。
今回のアプリケーションはread heavyなワークロードなのでリードレプリカが効くかと思ったのですが、自分が途中でミスってレプリケーションそのものに時間がかかったこと、組んだ構成が整合性チェックでどうしても通らなかったことで諦めたのも時間的には痛かったです。後から思えば、もっとオンメモリで処理できました。これは仕事ではないのでSREとしての自分を捨てるべきでした。
あとはキャッシュ実装が速さを優先するあまり初期化や再起動後の状態への意識を失っており、おそらく参加して初のfailでの終了となりました。これはあまりにも痛いです。いくら高スコアを記録しても、failしていては改善しないのと同じです。
良かったところを言うと、自分の役目は基本的に解析基盤を整え、アプリ担当が1コマンドで本番に変更を反映出来る状況にした時点で終わっていると言えなくもないです。後はX-Accel-Redirectでnginxに静的ファイルを捌く処理を移す改善を午前で終わらせられ、午後の余裕がなかったタイミングで取り組む必要が無かったのは心理的に非常に効きました。自分の経験値がまだまだだということがよく分かったので、参加して良かったです。運営の方々、今年もありがとうございました。
まとめ
Grafana Cloudはアプリケーションにできるだけ手を入れず、いつも通りの構成のままインフラ担当が裏から手を回して基盤を構築出来る便利なSaaSです。アプリ本体に手を入れれば、OpenTelemetryで分散トレーシングも可能です。無料枠も大きいので事前の練習などで使うのもおすすめです。
ISUCON12で初の本選出場を果たし、ISUCON13は逆にfailして失格しました。ラノベのセオリーとしては次は優勝のはずなので、来年も頑張ります。