はじめに
これはCybozu Advent Calendar 2021 7日目の記事です。是非他の記事も読んでみてください。
Kubernetesの名を聞くようになって久しく、皆様も業務・プライベート問わず日々YAMLを書かれていることでしょう。自分専用のプライベートクラスタが欲しいと思われている方もきっとたくさん居られるはず!今日は自分がプライベートで遊んでいるKubernetesクラスタを紹介したいと思います。
注意 この記事では私費で機材を購入したりプライベートでKubernetesについて学んだりしていますが、完全に筆者の趣味でありたまたま実益を兼ねているだけです。会社としてそれらの行為を指示及び推奨するものではありません。
なぜおうちKubernetes?
Docker DesktopのKubernetes、minikube、kindなどで手軽にクラスタを建てることができ、簡単な開発環境であれば非常に容易に作成することができるのもKubernetesの魅力です。
しかし、これらで作成したクラスタはクラウドプロバイダの提供するマネージドサービスと比較していくつか足りない機能があります。
type: LoadBalancerなサービスを使えない/使うのが大変PersistentVolumeClaimはlocal-path-provisionerか、hostPathでPVを用意するくらいしかない- そもそも一台のマシンの上で動いているので、複数のマシンからアクセスするのに向いていないし動かし続けるのに向いていない
などなど、ちゃんと独立したクラスタで自由にやりたくなります。ではなぜクラウドプロバイダのマネージドKubernetesではなく、わざわざオンプレミスなのか?
……。
家にKubernetesクラスタがあるとなんかかっこいい
ではやっていきましょう!*1
ハードウェアの選定
情報収集していると、Raspberry Piを使ってクラスタを組んでおられる方が多いようです。
RasPiの小さなクラスタも非常にかわいらしく魅力的なのですが、世は大半導体不足時代、Raspberry Piの値段も高止まりしていますし在庫も全然ありません。
PoE Hatを買ったりPoEスイッチを買ったりmicroSDは不安だからSSDで……とかやっているとコスト的にも中古でx86のPCを購入するのと大差無いことに気付いたため、NUCを中古で4台購入しました。

小さくてかわいいですね。2コア4スレッド、メモリ最大32GB搭載可能なモデルです。SSDはM.2 NVMeなものを一つ搭載できるのみ、NICも一つしかないのが不満ではありますが、まぁ実用上困ることはないでしょう。

vPro対応プロセッサーを搭載しており、Intel AMT*2によってリモート電源管理可能なProモデルです*3。
NUC本体が4台で7万円、8GBメモリを4枚・500GB SSDを4枚で4万円、合計11万円程度で揃いました。
クラスタのブートストラップ
cybozuのKubernetesクラスタはsabakan、そしてCKEを用いて管理されています。
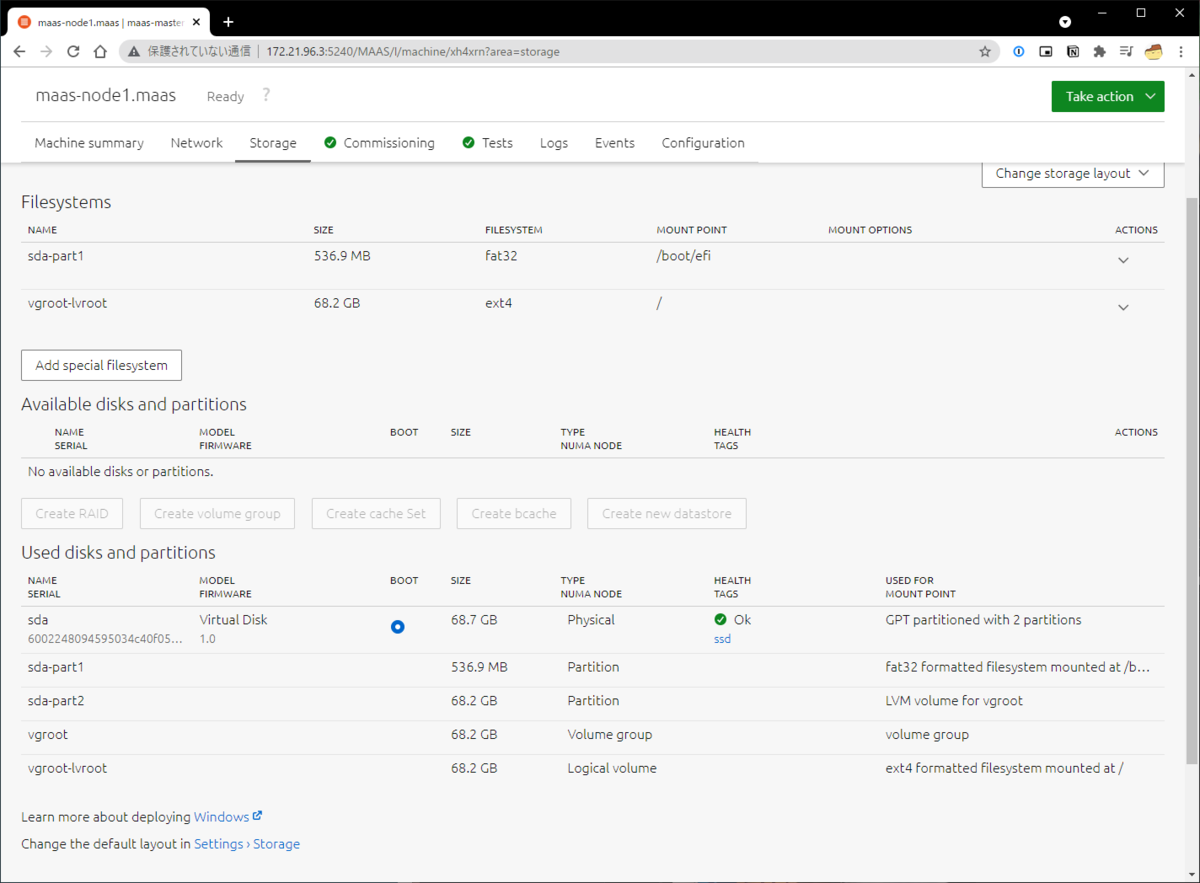
これらを使うことも検討しましたが、Intel AMTをサポートしているMAAS*4がいいかんじだったので、MAAS + kubesprayでクラスタを構築することにしました。MAASは家に元々あったサーバにインストールしています。
最初にIntel AMTの設定をしておけば、後は自動でUbuntuをインストール・セットアップすることができるようになりました。各NUCにディスプレイやキーボードを繋いで何度も試行錯誤したりする必要が無く便利です。ただしMAASがDHCPサーバなどを提供するため、家の中で他の端末が使うものとは別のVLANを切ってそこで運用しています。
cybozu-go/neco-apps
ここまでで素のKubernetesクラスタはたちましたが、このままではちょっとスペックのいいMinikube程度の機能しか無いので、どんどんコンポーネントをデプロイしていきます。
まず、やりたいことを決め、それを実現できるコンポーネントをデプロイすることにしました。自分が当初決めた要件は以下の通りです。
type: LoadBalancerなServiceを利用できる。これには指定した特定のレンジのIPアドレスを割り当てることができること。- 自動でSSL証明書を発行・更新し、httpsでサービスを提供できる。
- なんらかのIngress controllerによってリクエストのルーティングができる。
PersistentVolumeClaimを使ってデータの永続化領域を動的に切り出して利用できる。ノード障害耐性があるとよい。- GitOpsによって外部からアクセスさせることなくサービスをCDできる。
- メトリクスの収集・可視化、および監視ができる。
これらを実現するためには様々なコンポーネントが利用可能ですが、一体何を選択すればいいのか……
うーん……
あっ、cybozu-go/neco-appsで実際に使われているコンポーネントが公開されてるじゃーーん! github.com
ということで勝手に参考にしました。
注意 筆者はNecoのプロジェクトメンバーではありません。以下は勝手に参考しているだけです。
Metallb
おうちKubernetesでLoadBalancerを使うためには実質ほとんど選択肢がありませんでした。
MetallbはKubernetesにおいてtype: LoadBalancer なServiceを提供するためのコンポーネントです。BGPで経路を広告するBGPモードと、ARP*5を使ってVIPに紐付くノードの付け替えを行うL2モードがあります。BGPモードの場合はルータ側でECMP(Equal-cost multipath)を使うことで複数のノードに分散してトラフィックを送ることができますが、L2モードの場合はリーダーとなった特定のノードのみにトラフィックが集中します。今回は、一般的なルータでも利用可能なL2モードを利用することにしました。
Kubesprayのオプションを有効にすることでインストールできるのでそれを使いました。設定方法は https://kubespray.io/#/docs/metallb にある通りです。指定したIPアドレスレンジからtype: LoadBalancerなServiceにアドレスを割り当てるので、他と被らないレンジを指定します*6。MAASのUIからDHCPで割り当てたくないIPアドレスレンジを指定できるので、それを使ってLoadBalancer用のIPアドレスレンジを確保しておく必要がありました。
cert-manager
おなじみ証明書管理のためのコンポーネントです。特に説明することは無いと思います。
これもKubesprayでインストールできるため、それを使いました https://kubespray.io/#/docs/ert_manager。証明書発行はLet's Encryptを、マネージドDNSサービスとしてGoogle Cloud DNSを利用しています。便利な時代に感謝🙏
Contour
ContourはHTTPProxyというカスタムリソースを使うIngress controllerです。その実態としてはEnvoyのコントロールプレーンです。HTTPProxyリソースは個人的にはIngressよりも好きです。
インストールする方法は非常に簡単で、以下にあるものをほぼそのまま利用するだけです。自分はkustomizeを使ってイメージのバージョンを固定、リソースの設定を追加しました。
HTTPProxyリソースはIngressリソースよりも簡便に書けて良いと自分は思っていますが、一方で他のコンポーネントとのインテグレーションはIngressと比べると弱いです。例えばcert-manager用にアノテーション付与することにより証明書を自動発行する機能などは利用できません。そのためCybozuではHTTPProxyリソースを監視し、ExternalDNSのためにDNSEndpointリソースを、cert-managerのためにCertificateリソースを自動で生成する機能を追加したカスタムコントローラであるcybozu-go/contour-plusを開発・利用しています。これによりHTTPProxyリソースを作るだけで以下を追加で自動的に行うようにしています。
- DNSレコードの登録
- 証明書の発行
今回自分は外部へのサービス公開をほとんど考えていない*7ことから採用をスキップしましたが、非常に便利なので外部にサービス公開を考えている場合は是非使ってみてください。
TopoLVM
Cybozuが開発・運用している、LVMを使ってPersistentVolumeを提供するCSIプラグインです。詳しくは以下をご覧下さい。
後述するRookでPVC basedなクラスタを構築したり、mocoでMySQLクラスタを構築するために利用しています。PVとノードが紐付くため、そのノードが利用できなくなった場合そのPVの情報は失われてしまいます。利用する側でデータの冗長性を確保する必要があります。
Kubernetes v1.21からbetaとなったGeneric Ephemeral Volumeとして利用することもできます。TopoLVM用のVGからボリュームを切り出すため、emptyDirでホストOSのストレージ領域が圧迫されてしまうことを防ぐことができます。
Rook
分散ストレージソフトウェアであるCephをKubernetesで管理するためのオペレータです。CephやRookについては以下の記事をご参照ください。
TopoLVMによってPVCからDynamic Provisioningできるようになっているため、RookではPVC basedなクラスタを作成しました。id:tenzen_hgst さんの以下の記事を参考にしました。
とはいえ今回のクラスタには3つのワーカーノード、各ノードに1台のストレージが載っているのみなので、大きめのボリュームのOSDが各ノードに一台いるという感じの簡単な構成になっています。あんまりOSDの割り当てなどで悩む余地もありませんでした。Rook/Ceph全然わからんと言いながら使っています。
TopoLVMとは異なり、可用性のあるPVを提供することができます。また、S3互換なAPIを備えたオブジェクトストレージも提供しており、Minioなどを別途建てなくてもオブジェクトストレージを利用できます。やはりオブジェクトストレージがあるとぐっとクラウドネイティブっぽくなりますね(?)。
https://rook.io/docs/rook/v1.7/ceph-object.html
SealedSecret
GitOpsのためにはSecretもGit管理したいところですが、プライベートリポジトリにしたとしても流出に備えて暗号化できるならしておきたいところです。BitnamiのSealedSecretコントローラとkubesealコマンドを使えば、簡単に既存のSecretを暗号化して利用することができます。
詳しい導入・利用方法については他のサイトに譲りますが、ArgoCDでいつまで経ってもSealedSecretのSyncが完了しない問題がv0.17.0で解消している*8ので紹介しておきます。
ArgoCD
GitOpsのためのコントローラです。おうちKubernetesでは可能な限り外側に露出するアタックポイントを減らして、毎日メンテできない不安を軽減したいものです。GitOpsならば、外側からアクションを実行するような口を開けることなく継続的にアプリケーションをデプロイすることができます。他に有名なGitOpsのためのツールとしてFlux 2などが知られています。
基本的なインストール方法は公式ドキュメントの通りです。ただし一部いじりたい箇所もあったので、kustomizeを使って一部変更しています。
GitHubアカウントでSSOする
一人なのでadminのパスワードをkubectlコマンドでぶっこ抜いて使っても良いのですが、せっかくなのでGitHubでSSOすることにしました。まず認証のためのorgが必要なので、適当なorgを用意します。そのorgの設定から、GitHubのOAuth Applicationを用意します。
用意したOAuth AppのClient IDとClient Secretを用意し、Secretリソースとして作成します。実際にはこれをkubesealコマンドを使ってSealedSecretリソースとして暗号化しています。
apiVersion: v1 kind: Secret type: Opaque metadata: name: argocd-github-client-secret namespace: argocd spec: stringData: clientID: Client ID clientSecret: Client Secret
上記Secretを使うようにArgoCDを設定します。以下は最低限の設定です。必要な他の設定は公式のサンプルを見てください。
apiVersion: v1 kind: ConfigMap metadata: name: argocd-cm data: # ArgoCDにアクセス可能なURLを指定する。コールバックのFQDNもここを指す。 url: https://argocd.sample.com # falseならばadminユーザを作成しない admin.enabled: "false" dex.config: | connectors: - type: github id: github name: GitHub config: # $シークレット名:key の形で指定する clientID: $argocd-github-client-secret:clientID clientSecret: $argocd-github-client-secret:clientSecret orgs: # どのorgを許可するか - name: org名 teamNameField: slug --- apiVersion: v1 kind: ConfigMap metadata: name: argocd-rbac-cm data: # どのorgのどのteamにどの権限を割り当てるか。roleはadminとread-onlyのみがデフォルトで用意されている。 # https://argo-cd.readthedocs.io/en/stable/operator-manual/rbac/#basic-built-in-roles policy.csv: | g, org名:team名, role:admin # どのチームにも所属しないユーザに何を割り当てるか。空文字にすると何も割り当てない == 閲覧権限すら無し。 policy.default: ""
これらを適用することでArgoCDにGitHubでログインするボタンが表示されるようになります。
gRPC用とWeb UI用でサービスを分ける
neco-appsを見ていると、ArgoCD Server用になぜか2種類のserviceがあることに気付きました。
- neco-apps/service.yaml at release-2021.12.01-27858 · cybozu-go/neco-apps · GitHub
- neco-apps/service.yaml at release-2021.12.01-27858 · cybozu-go/neco-apps · GitHub
片方には projectcontour.io/upstream-protocol.tls: 443,https が、もう片方には projectcontour.io/upstream-protocol.h2: 443,https が付いています。これらはContour用のannotationで、EnvoyでTLS終端せずにupstreamのサービスにプロキシするための設定です。
https://projectcontour.io/docs/v1.19.1/config/upstream-tls/
どうもContourは同じホスト・ポートに対して異なるプロトコル(http/https or gRPC (http/2))でサーブすることを許していないようで、うまく動かなくなってしまうという挙動に対するワークアラウンドのようです。2つのアノテーションを一つのServiceに付与して動かしてみたりもしましたが、実際にargocdコマンドがうまく動かなかったりしたため自分も同様に二つのServiceに分けました。HTTPProxyリソースの書き方は下記の通りです。
neco-apps/httpproxy.yaml at release-2021.12.01-27858 · cybozu-go/neco-apps · GitHub
VictoriaMetrics
普通にPrometheusを使っても良かったのですが、下記の記事を読んでVictoriaMetricsを使ってみることにしました。
おうちKubernetesをやる上で嬉しいこととしては、以下の辺りでしょうか。
https://docs.victoriametrics.com/Single-server-VictoriaMetrics.html#prominent-features
- It uses 10x less RAM than InfluxDB and up to 7x less RAM than Prometheus, Thanos or Cortex when dealing with millions of unique time series (aka high cardinality).
- It provides high data compression, so up to 70x more data points may be crammed into limited storage comparing to TimescaleDB and up to 7x less storage space is required compared to Prometheus, Thanos or Cortex.
- It is optimized for storage with high-latency IO and low IOPS (HDD and network storage in AWS, Google Cloud, Microsoft Azure, etc). See disk IO graphs from these benchmarks.
まとめるとRAMの使用量が少ない!データの圧縮率が良い!遅いストレージでも大丈夫!(今回はNVMe SSDだけど)
特にストレージ容量は比較的小さめであることが多いと思うので、データ圧縮率が良いのは嬉しいですね。加えて比較的構成がシンプルであることも地味に嬉しい点です。理解が楽なので。
今回はVictoria Metrics operatorを使ってクラスタを構築しました。導入自体は割と簡単です。
全然不要なのに調子に乗ってHA構成で組んだので、そのうち飽きたら解体します。今のところちゃんと動いていて良さそう。
Grafana operator
VictoriaMetricsはWeb UIを持たないので、可視化のためにGrafanaを入れます。GitOpsしたいのでGrafana operatorを導入し、ダッシュボードやデータソースをコードで管理します。また、せっかくArgoCDではGitHubでSSOするようにしたので、Grafanaも同様にします。↓いろいろ省略して認証周りのみに絞っています。
apiVersion: integreatly.org/v1alpha1 kind: Grafana metadata: name: grafana spec: config: auth: disable_login_form: False disable_signout_menu: True auth.anonymous: enabled: False # GitHubでのSSOの設定 auth.github: enabled: true allow_sign_up: true scopes: user:email,read:org auth_url: https://github.com/login/oauth/authorize token_url: https://github.com/login/oauth/access_token api_url: https://api.github.com/user allowed_organizations: org名 server: domain: 公開するドメイン名 root_url: https://公開するドメイン名 users: viewers_can_edit: true auto_assign_org_role: Viewer deployment: envFrom: - secretRef: # このsecretにclient idやclient secretを入れておく name: grafana-github-client-secret
Secretでは特定の環境変数に値を渡します。この辺りの設定はこことかここにあるので、その辺りを参照すれば他のプロバイダでもSSO出来ると思います。
apiVersion: v1 kind: Secret type: Opaque metadata: name: grafana-github-client-secret spec: stringData: GF_AUTH_GITHUB_CLIENT_ID: Client ID GF_AUTH_GITHUB_CLIENT_SECRET: Client Secret
DataSourceも適当に足します。今のところVictoriaMetricsしかいないのでこれだけです。
apiVersion: integreatly.org/v1alpha1 kind: GrafanaDataSource metadata: name: vm-source spec: name: victoriametrics.yaml datasources: - name: victoriametrics type: prometheus access: proxy # vmselectのserviceを指定 url: http://vmselect-vmcluster.monitoring.svc:8481/select/0/prometheus version: 1 isDefault: true editable: false jsonData: tlsSkipVerify: true timeInterval: "30s"
ダッシュボードも grafana.comで公開されているダッシュボード は以下の様に簡単に追加できます。例えばNode Exporterのダッシュボードのrevision 23をデプロイする場合は以下のようにします*9。
apiVersion: integreatly.org/v1alpha1 kind: GrafanaDashboard metadata: name: node-exporter spec: url: "https://grafana.com/api/dashboards/1860/revisions/23/download" datasources: - inputName: "DS_PROMETHEUS" datasourceName: "victoriametrics"
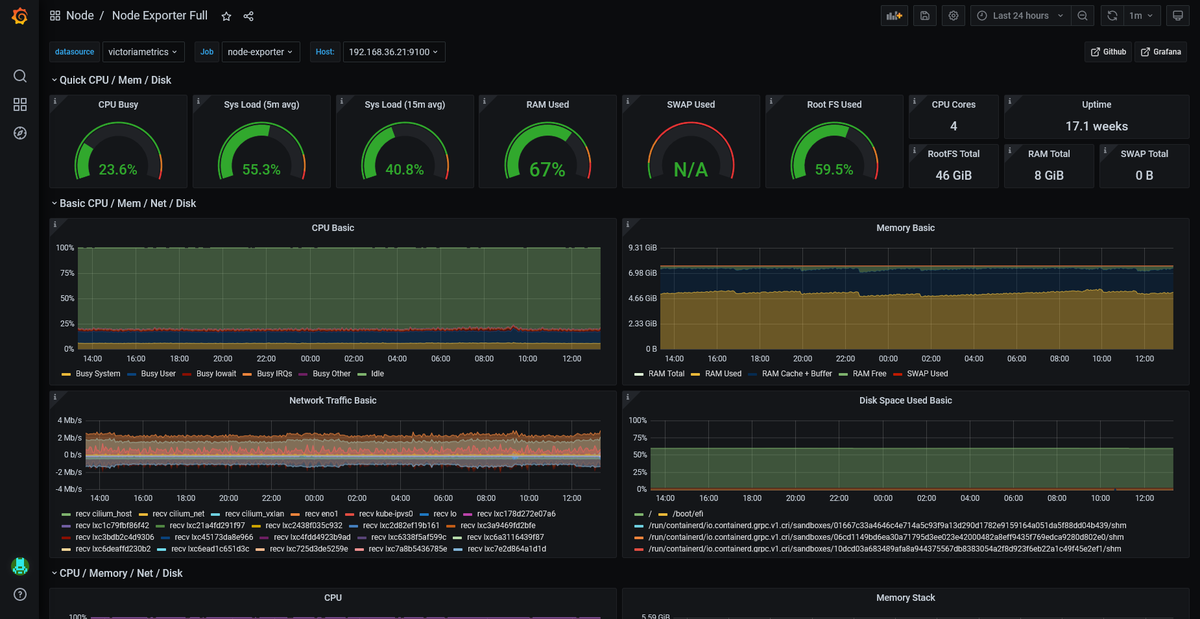
各NodeにNode Exporterをたてておき、VMNodeScrapeリソースなどを使って情報を収集させておけば以下の様にダッシュボードを表示できます。
moco
ここまでで基本的なことはだいたいできるKubernetesクラスタができました。ついでなのでもう一個使えるコンポーネントをデプロイしておきます。
mocoはCybozuが開発しているMySQLオペレータで、MySQLのSemi-sync replicationを使ったクラスタを提供します。使い勝手が通常のMySQLと変わらないこと、最悪どうしようもなくなったら社内で聞けばなんとかなるやろと思ったので導入してみました。インストールも↓のドキュメントに従うだけでよく、非常に簡単です。
作成するMySQLClusterリソースで永続化ボリュームの大きさを指定できるのですが、例では1GBとなっています。自分の手元では容量不足で起動しなかったりしたため、5~10GB程度は割り当てておくと良いと思います。またnameは mysql-data で固定です。最初適当な名前を付けて失敗しました*10。
apiVersion: moco.cybozu.com/v1beta1 kind: MySQLCluster metadata: name: test spec: ... volumeClaimTemplates: - metadata: name: mysql-data spec: accessModes: [ "ReadWriteOnce" ] resources: requests: storage: 10Gi
開発環境
大きな変更をいきなり本番クラスタに当てるのは怖いですよね。というわけでおうちKubernetesクラスタも開発環境を用意するようにしました。
クラウドでインスタンスを作ることも考えましたが、たまたま手元にそこそこスペックの良いWindowsデスクトップマシンがあるので、これにVMを立てまくることにしました。
- CPU:Ryzen7 3700X(8コア 16スレッド)
- RAM:64GB
- SSD:2TB
VMを5つ建てます。それぞれ以下の役割を持ちます。
- maas-master:MAASをインストールしておくサーバ
- maas-node1:KubernetesのMasterノード
- maas-node2:KubernetesのWorkerノードその1
- maas-node3:KubernetesのWorkerノードその2
- maas-node4:KubernetesのWorkerノードその3
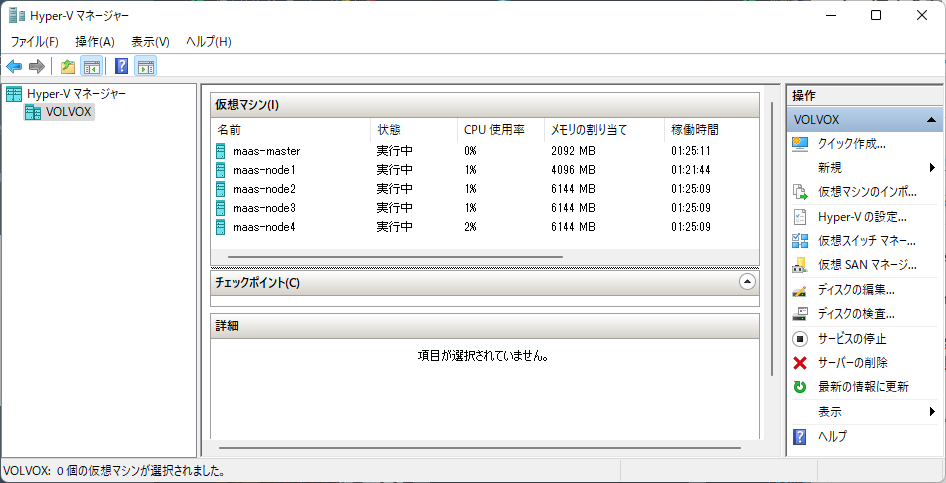
雑に作っていったらスペックがまちまちになってしまい、でもまぁ困ってないのでいいかなということでそのままになっているという雑な図です。動作確認のためにデスクトップPCを起動しておく必要があるとか、GitOpsでデプロイはできるが外部からのアクセスは許可していないので実質開発環境がこのデスクトップPCに固定化されているところがイケてないところです。
基本的にこの環境で動作を検証し、問題なければ変更をreleaseブランチにマージ→本番環境のArgoCDがそれをsyncして適用という流れになっています。とはいえ本番環境でしか起きない問題なども度々引いており、なかなかうまくいかないなという感じです*11
今動いているもの
汎用的なWebクローラーのようなものを書いて新着通知をしたりしています。特に速報性は求めていないのでかなり緩やかなペースでの通知ですが、DBがないとつらくAWS LambdaやGoogle Cloud Functionsに地味に乗せづらかったものです。DBスキーマの変更までGitOpsで完結しているので、コードを書いてリリースまでクラスタに触れる必要がありません。このあたりについてはまたいずれ記事を書ければ良いなと思っています。
他は気になった物をときどきデプロイする程度で、あまり安定的に動いてるコンポーネントはありません。何か面白いものを思いつくのを待っています。
これからやりたいこと
バックアップとリストア
今のところRook/Cephが崩壊するとデータを全ロストします。うちにはNASもあるので、定期的にデータのバックアップを取りたいところです。また、バックアップは取っただけでは意味が無く、それをリストアできる必要があるのでリストアの方法についても探求していきたいと思っています。 おうちクラスタでは軽い気持ちでバージョン上げたり新しいものを入れたりしがちな上、壊れると直すのが面倒になって放置しがちです。最悪クラスタを一度壊して作り直してもOKという体制を整えて長く使ってあげたいですね。
監視の充実
VictoriaMetricsとGrafanaを入れたとはいえ、まだまだ中身が追いついていません。少しずつ拡充していければなと思っています。PromQLが難しすぎる……
まとめ
- おうちKubernetesクラスタをIntel NUCで組みました
- プロダクション環境で動作しているcybozu-go/neco-appsを参考にデプロイするコンポーネントを決め、実際に運用しています
- 楽しいよ
以上です。皆さんの素敵なおうちKubernetesクラスタ情報お待ちしております。
明日以降のCybozuアドベントカレンダーもお楽しみください!
*1:真面目なことを言っておくと、現実世界の複雑な部分をクラウドプロバイダに押し付けっぱなしにするだけでなく、自分で体感した方がよいと思っているためです。やればやるほどマネージドサービスのすごさを体感できて安く感じるのでお得です。
*2:インテル® アクティブ・マネジメント・テクノロジー (インテル® AMT) | インテル
*3:NUCでvPro対応しているものは非常に少ないためレアですが、LenovoやDELL・HPなどから出ている小型PCには対応しているものが豊富にあります。入手性はそれらの方が良いでしょう。
*6:ここで割り当てるIPアドレスはプライベートIPアドレスです。外部にサービスを公開したい場合、ルータのNAPTを使ってルーティングする必要があります。
*7:主に家の中で引ければ良いので、名前解決にはルータ搭載の簡易DNSサーバを使っています。証明書は必要ですがDNS-01チャレンジならばHTTPサーバを公開しておく必要もなく、外部に一切公開せずに運用が可能です
*8:正確にはv0.16.0の時点で追加のフラグを与えることで解消できるようになり、v0.17.0でそのオプションがデフォルトで有効化されました。 github.com
*9:適用直後しばらくはダッシュボードの取得時に Too Many Requests のようなエラーが出ていたのですが、しばらく放置すると取得できたのかダッシュボードが見れるようになっていました
*10:ちゃんとドキュメントを読め……
*11:逆にGrafana operatorでは自分の開発環境でのみ起きる問題を引き当ててしまい、現状本番環境に当てないと動作確認できないという最悪な状況になったりもしています。 github.com