cache-hitとは
GitHub Actionsのキャッシュ用actionであるactions/cacheは、指定したキーに完全一致するキャッシュがヒットしたかどうかのパラメータをそのstepのoutputとして保持している。 つまり以下の様にすることで、キャッシュがヒットしたかどうかを判定し、何かアクションするということが可能である。
jobs: run: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: actions/cache@v4 id: cache with: path: ./cache-dir key: your-cache-key - if: steps.cache.outputs.cache-hit != 'true' run: | # something to do
また、actions/cache(およびactions/cache/restore)のREADMEには以下の様に記載されている。
https://github.com/actions/cache?tab=readme-ov-file#outputs
https://github.com/actions/cache/blob/main/restore/README.md
Note cache-hit will only be set to true when a cache hit occurs for the exact key match. For a partial key match via restore-keys or a cache miss, it will be set to false.
restore-keysで前方一致するキャッシュにヒットしたときや、何もヒットしなかったときにはfalseがセットされると書かれている。 実際にv3まではこのような挙動であった。
v4における挙動変更(?)
自分は以前紹介したactions/cache/saveとactions/cache/restore*1を使って、デフォルトブランチでのみキャッシュをsaveし、トピックブランチではrestoreのみを行うというワークフローを組んでいた。具体的には以下の様に記載していた。
on: push: branches: - main pull_request: branches: - main jobs: build: on: ubuntu-22.04 steps: - uses: actions/checkout@v3 - uses: actions/setup-go@v4 with: go-version-file: go.mod # 自分でキャッシュをハンドルするので無効にしておく cache: false - uses: actions/cache/restore@v3 id: restore-go-cache with: path: | ~/go/mod ~/.cache/go-build key: go-cache-${{ runner.os }}-${{ runner.arch }}-${{ github.sha }} restore-keys: | go-cache-${{ runner.os }}-${{ runner.arch }}- go-cache-${{ runner.os }}- - run: | # something to do - uses: actions/cache/save@v3 # mainブランチ上での実行時かつ、キャッシュがヒットしなかった場合のみ if: github.ref_name == 'main' && steps.restore-go-cache.outputs.cache-hit == 'false' with: path: | ~/go/mod ~/.cache/go-build key: ${{ steps.restore-go-cache.cache-primary-key }}
実際これは上手く動作しており、v3の間は特に問題なかった。actions/cacheをv4に変更しても、特にエラーなどは生じていなかった。ワークフローが走りきったので、自分はそこでOKと判断ししばらく忘れていた。
しかしあるときから、なぜかCI中のビルド時間が伸びていることに気付いた。よく見ると、キャッシュがヒットしていない。mainブランチのワークフローが失敗せず走りきっているのに、キャッシュがヒットしないとはどういうことだ???
cache-hitがfalseを返さない
actionsの実験用に持っているリポジトリでこれを検証することにした。簡単のためgoは使わず以下の様なワークフローを組んで cachemiss ブランチとしてpushしてみた。
name: cache on: [push] jobs: save: runs-on: ubuntu-22.04 steps: - uses: actions/checkout@v4 - uses: actions/cache/restore@v4 id: restore with: path: .cache key: test-${{ runner.os }}-${{ runner.arch }}-${{ github.sha }} restore-keys: | test-${{ runner.os }}-${{ runner.arch }}- - run: | echo "steps.restore.outputs.cache-hit=${{ steps.restore.outputs.cache-hit }}" echo "github.ref_name=${{ github.ref_name }}" mkdir -p .cache echo ${{ github.sha }} > .cache/sha - uses: actions/cache/save@v4 if: github.ref_name == 'cachemiss' && steps.restore.outputs.cache-hit == 'false' with: path: .cache key: test-${{ runner.os }}-${{ runner.arch }}-${{ github.sha }}
すると、どうやらv4になって以降、primary keyにヒットしなかったとき cache-hit というoutputが空文字を返すようになってしまっていることが分かった。
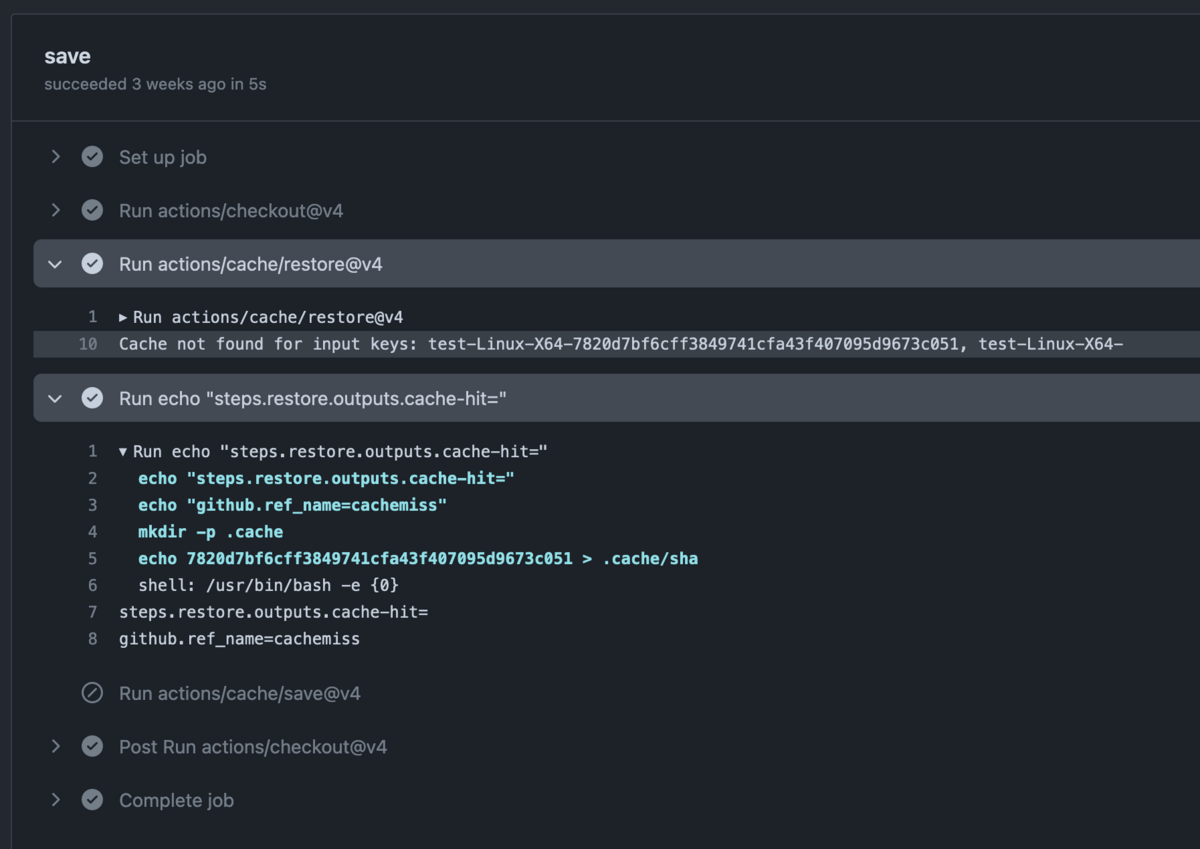
これによりmainブランチで実行すると github.ref_name == 'main' && steps.restore.outputs.cache-hit == 'false' という条件では
github.ref_name == 'main'→'master' == 'master'→ truesteps.restore.outputs.cache-hit == 'false'→'' == 'false'→ false
となり、このステップが単にスキップされてしまったようだ。
ワークアラウンド
ワークアラウンドというか……実は actions/cache のREADMEやGitHub本体のドキュメントを読んでいると outputs.cache-hit == 'false' はどうやら使われていないようだ。
- actions/cacheの最初のコミット
- https://github.com/actions/cache/blob/37c45447e4220b80ffd0f1b418c35f1a1808d204/README.md#skipping-steps-based-on-cache-hit
if: steps.cache.outputs.cache-hit != 'true'
- GitHub Actionsのドキュメント
- https://docs.github.com/en/actions/using-workflows/caching-dependencies-to-speed-up-workflows#using-the-output-of-the-cache-action
if: ${{ steps.cache-npm.outputs.cache-hit != 'true' }}
自分が以前調べた時は == 'false' だった気がするのに……と思ったところ、どうもドキュメントの方が修正されたらしい。
いやだったら false を返すって記述は消した方が良かったし、v4のbreaking changeに書いておいて欲しかったよ……??
何も書いてないじゃん……
Release v4.0.0 · actions/cache · GitHub
というわけで、なんかこう納得いかないですが皆さん cache-hit != 'true' を使いましょう。
気になった方は是非↓のissueにupvoteしてもらえると、もしかしたら(ドキュメントの方か実装の方かわからないけど)修正されるかもしれないのでよろしくお願いします。
