マルチアーキテクチャ対応イメージのビルドをどうにか早くしたかった
マルチアーキテクチャ対応イメージって何?
最近ではApple Siliconの登場や、Oracle CloudのAmpere A1 Computeインスタンスなど、ARMアーキテクチャ採用のプロセッサに実際の開発などで触れる機会も増えてきました。 現在広く流通するx86_64に対応するIntelやAMD製のプロセッサと比べて、ARM系のCPUには高い省電力性能などに期待が集まっています。趣味開発レベルの話をすると、Oracle CloudのAlways FreeなA1インスタンスは非常に魅力的であり、是非活用したいところです。
ただしARM系CPUではx86_64向けにビルドされたバイナリをそのまま動かすことはできません。当然Dockerイメージについてもx86_64向けのイメージをarm64のマシンで動かすことはできない*1ため、arm向けにビルドされたDockerイメージを別で用意する必要があります。簡単に思いつく方法としては
- イメージごと分けてしまう方法
- 例:
hoge/fuga-arm64:latest,hoge/fuga-amd64:latest
- 例:
- タグごとに分けてしまう方法
- 例:
hoge/fuga:latest-arm64,hoge/fuga:latest-amd64
- 例:
などがあると思います。しかし、これは利便性を大きく損ないます。docker-compose.ymlだったり、コンテナを起動するスクリプトだったり、Kubernetesのマニフェストだったりには基本的にイメージ名やタグがハードコードされています。環境ごとにこれを書き換えるのは非常に面倒でしょう。
マルチアーキテクチャ対応イメージとは、ある単一のイメージおよびそのタグに、複数のアーキテクチャ向けのイメージを紐付けたものを指します。利用者側で自身のアーキテクチャに合わせて最適なイメージが選択されて使用されるため、アーキテクチャを意識してイメージ・タグを書き換える仕組みを用意する必要がありません。例えばDocker Hubで配布されているベースイメージ( docker.io/library/* )などが多数のアーキテクチャに対応したマルチアーキテクチャ対応イメージになっています*2。
どのアーキテクチャに対応しているか、Dockerとしてのサポートの範囲などは以下に記述があります。 https://github.com/docker-library/official-images#architectures-other-than-amd64
どうやって作るか
単に別アーキテクチャでビルドして同じイメージ・タグでレジストリにpushすると、後からpushされた方で上書きされて単一のアーキテクチャ向けのイメージになってしまいます。正しいマルチアーキテクチャ対応イメージの作り方には大きく分けて2つの方法があります。
docker manifestコマンドを使う
どうにかして各アーキテクチャで動く環境を手に入れ、その上でdocker buildしたイメージを別々のイメージ名ないしタグでレジストリにpushしておきます*3。ここでは例えば amd64/image:latest と arm64/image:latest としておきます。これらをまとめて一つの my/image:latest としたい場合、下記の様にコマンドを実行します。
docker manifest create my/image:latest \
amd64/image:latest \
arm64/image:latest
これで my/image:latest のマニフェストができたのでこれをレジストリにpushします。
docker manifest push my/image:latest
この方法は(おそらく)Docker Hubのオフィシャルイメージで使用されています。例えばUbuntuのイメージは対応アーキテクチャごとにそれぞれ別々のorgに存在します。
- amd64: https://hub.docker.com/r/amd64/ubuntu/
- arm64v7: https://hub.docker.com/r/arm32v7/ubuntu/
- arm64v8: https://hub.docker.com/r/arm32v8/ubuntu/
利用者側では単にubuntu:20.04などのイメージを指定するだけで、適したアーキテクチャのイメージがpullされます。
docker buildxコマンドでビルドする
buildxとは、BuildKit*4に基づいてより発展的なビルド方式を提供するdockerコマンドのプラグインです。
buildxではQEMUを利用した他アーキテクチャのエミュレーション環境や、実際にそのアーキテクチャで動作するノードを仮想的な Builder に紐付け、それらを使ってビルドを行い、最初からマルチアーキテクチャに対応したマニフェストを用意することが出来ます。 ただし、ローカルのDocker環境からマルチアーキテクチャのマニフェストをそのまま取り扱うことはできないため、一度レジストリにpushした後に自身のアーキテクチャに対応するイメージをpullすることでしかそのビルドしたイメージを使うことは出来ません。
試した環境の情報は以下の通りです。
- macOS 11.6
- MacBook Pro (13-inch, 2019) Intel Core i5
- Docker Desktop for Mac 4.0.1 (68347)
- Docker CLI 20.10.8
- Docker Engine 20.10.8
- Docker buildx 0.6.1
まずはBuilderを用意します。ここではDocker Desktop for Macを使っています。WindowsのDocker Desktopではおよそ同じ手順で出来るとは思いますが、Linuxでは追加の手順が必要になると思います*5。本当はLinuxでも確かめるつもりだったのですが、諸事情でデスクトップが死んでいるので諦めました*6。
ローカルでマルチアーキテクチャ対応イメージをビルドする場合、docker-container ドライバの Builder を作ることが必要です。
docker buildx create \
--name multi-arch-builder \
--driver docker-container \
--platform linux/arm64,linux/amd64
今回はサンプルとしてGo製のcowsayであるNeo-cowsay*7をビルドするだけのDockerfileを用意してみました。 golangイメージはマルチアーキテクチャ対応しているので、Dockerfile自体に工夫がなくともamd64/arm64両方に向けてビルドできます。
FROM golang:1.17.1 as builder ARG VERSION=latest RUN go install github.com/Code-Hex/Neo-cowsay/cmd/cowsay@${VERSION} FROM gcr.io/distroless/static COPY --from=builder /go/bin/cowsay /usr/bin/cowsay ENTRYPOINT ["/usr/bin/cowsay"]
先ほどの Builder を指定して、linux/amd64 と linux/arm64 向けにビルドしてみます。
$ docker buildx build \
--builder multi-arch-builder \
--platform linux/amd64,linux/arm64 \
-o type=image,push=false \
-t cowsay:latest \
--no-cache .
[+] Building 91.3s (15/15) FINISHED
=> [internal] load build definition from Dockerfile 0.4s
=> => transferring dockerfile: 274B 0.0s
=> [internal] load .dockerignore 0.3s
=> => transferring context: 2B 0.0s
=> [linux/arm64 internal] load metadata for gcr.io/distroless/static:latest 1.0s
=> [linux/arm64 internal] load metadata for docker.io/library/golang:1.17.1 1.4s
=> [linux/amd64 internal] load metadata for docker.io/library/golang:1.17.1 1.3s
=> [linux/amd64 internal] load metadata for gcr.io/distroless/static:latest 1.4s
=> CACHED [linux/amd64 stage-1 1/2] FROM gcr.io/distroless/static@sha256:912bd2c2b9704ead25ba91b631e3849d940f9d533f0c15cf4fc625099ad145b1 0.0s
=> => resolve gcr.io/distroless/static@sha256:912bd2c2b9704ead25ba91b631e3849d940f9d533f0c15cf4fc625099ad145b1 1.0s
=> CACHED [linux/amd64 builder 1/2] FROM docker.io/library/golang:1.17.1@sha256:285cf0cb73ab995caee61b900b2be123cd198f3541ce318c549ea5ff9832bdf0 0.0s
=> => resolve docker.io/library/golang:1.17.1@sha256:285cf0cb73ab995caee61b900b2be123cd198f3541ce318c549ea5ff9832bdf0 1.1s
=> CACHED [linux/arm64 stage-1 1/2] FROM gcr.io/distroless/static@sha256:912bd2c2b9704ead25ba91b631e3849d940f9d533f0c15cf4fc625099ad145b1 0.0s
=> => resolve gcr.io/distroless/static@sha256:912bd2c2b9704ead25ba91b631e3849d940f9d533f0c15cf4fc625099ad145b1 1.1s
=> CACHED [linux/arm64 builder 1/2] FROM docker.io/library/golang:1.17.1@sha256:285cf0cb73ab995caee61b900b2be123cd198f3541ce318c549ea5ff9832bdf0 0.0s
=> => resolve docker.io/library/golang:1.17.1@sha256:285cf0cb73ab995caee61b900b2be123cd198f3541ce318c549ea5ff9832bdf0 1.1s
=> [linux/amd64 builder 2/2] RUN go install github.com/Code-Hex/Neo-cowsay/cmd/cowsay@latest 17.1s
=> [linux/arm64 builder 2/2] RUN go install github.com/Code-Hex/Neo-cowsay/cmd/cowsay@latest 80.5s
=> [linux/amd64 stage-1 2/2] COPY --from=builder /go/bin/cowsay /usr/bin/cowsay 1.0s
=> [linux/arm64 stage-1 2/2] COPY --from=builder /go/bin/cowsay /usr/bin/cowsay 0.9s
=> exporting to image 5.5s
=> => exporting layers 4.0s
=> => exporting manifest sha256:d1ee75cd239140bd0210554ada9707162750d4766635e6abc17725aa70bac5d3 0.3s
=> => exporting config sha256:afe4e4a473376655e0377c92aa75ef7bdcddc3a3fffd95e285fda7d0db4ce1df 0.3s
=> => exporting manifest sha256:df3198ab96b70b1e5b0584d5cc39065772c1268946e088e0bb2f1f038ff81400 0.3s
=> => exporting config sha256:af3de61b4d4202ee4c8fa513b189e620443a462b5487d39cc491fee08776d39d 0.3s
=> => exporting manifest list sha256:e1e7b18094b953f584370083971a13fdcc12290239e575739e0b7f91a9d83ca1 0.3s
無事イメージがビルドできたようです。とはいえ、これを使うためにはレジストリにpushする必要があるのですが…… 。現状生成されたマニフェストをdocker manifest inspect等で見ることもできないような気がします。見る方法を知っている方、教えてください🙏
ちなみに docker ドライバーのBuilderを使い、単一のplatformを指定し、-o type=image,push=false ではなく --load というオプションを組み合わせると、 docker image ls などで表示されるイメージ一覧にビルドされたイメージが追加されます。動作確認したい場合は試してみてください。
buildxとQEMUによるビルドは遅い
非常に簡単にマルチアーキテクチャ対応イメージをビルドすることができました。しかし、実行時間を見てみると、 go install してcowsayをビルドしている部分の時間は以下の様になっていました。
およそ5倍近い差が開いています。複数回実行しても、おおよそ4〜6倍程度、arm64向けのビルドが遅いことがわかりました。QEMUの分のオーバーヘッドがあるため仕方ないのですが、ビルド対象の規模が大きくなるほど遅くなる他、apt-getなど他の操作も有意に遅くなりました。場合によっては10倍、20倍と差が開くこともあり、CIなどで長時間待たされることになりました。
CIでのビルドを速くしたい
当初、プライベートリポジトリでマルチアーキテクチャ対応イメージをCIでビルド・pushしたいと考えていました。このリポジトリではCIにGitHub Actionsを用いています。GitHub Actionsは従量課金で毎月2000分のビルドまでは無料ですが、色々複雑なことをしていたら一回のビルド時間が容易に15分、20分と伸びていってしまいました。できれば課金はしたくないですし、手作業でビルド・pushもしたくありません。何より一度コードをpushしてから結果が分かるまで20分もかかるというのはかなり苦痛です。
どうにか高速化できないかなと少し足掻いてみました。試したリポジトリ・アップロードしたイメージは以下にあります。
https://hub.docker.com/repository/docker/pddg/multi-arch-image-sample
アーキテクチャごとに別ジョブでビルドする
buildx自体はビルドをリモートマシンに委譲できるなどスケーラブルな仕組みになっているのですが、CIの仕組みとは非常に相性が悪いです。CIでは定義された複数のジョブを決められたスペックのインスタンスで実行します。スケールする単位はジョブやワークフローごとであり、ある一つのジョブ内で計算リソースをスケールさせるためには動的にクラウドのリソースを作るようなことが必要になります*8。そんな面倒なことはしたくないので、対象アーキテクチャごとにジョブを分けて並列にビルド・レジストリにpushして、それらが全て完了した後に後続のジョブで docker manifest コマンドを叩く方法を検討してみました。

ただ今回は各アーキテクチャごとに別ジョブでビルドしても、ワークフロー全体に占める時間はほとんど変わりませんでした。より大規模なプロジェクトや、多数のアーキテクチャをサポートなどするなどすると差が出てくると思います。
クロスビルドを活用する
Goは幸いクロスビルドできる言語です。QEMUなんて挟まなくとも、Pure Goで記述されていればx86_64のマシンからarm向けのバイナリをビルドすることが出来ます。これを使えば、わざわざ重い環境でビルドしなくてもよくなるはずです。
実際に今回はこの方法で2分近くかかっていたCIを40秒程度まで短縮することが出来ました。
ただし嬉しくない点がいくつかあります。
- Dockerfile内でアーキテクチャを認識する必要があるかもしれない
- docker buildで完結しないため、開発者の個々の環境に左右される可能性がある
まず1についてですが、Goのアーキテクチャの指定方法と、Dockerのアーキテクチャの指定方法に差異があるため、これをどこかで吸収する必要があります。各アーキテクチャ向けにビルドしたい場合、ビルド時に以下の様に環境変数を設定します*9。arm64で GOARM=8 を付けると Invalid GOARM value. Must be 5, 6, or 7. というエラーが出るので注意が必要です。
GOOS=linux GOARCH=amd64 go build . GOOS=linux GOARCH=arm GOARM=7 go build . GOOS=linux GOARCH=arm64 go build .
Dockerfile内からこれらの値について知ることができる特殊な引数は以下の通りです。
# linux ARG TARGETOS # amd64, arm, arm64 ARG TARGETARCH # linux/arm/v7 のみ v7 。他は空文字。 ARG TARGETVARIANT
arm/v7の場合は TARGETVARIANT に値が存在しますが、amd64やarm64の場合は現状 TARGETVARIANT は空文字列です。もしかしたら将来的にarm64/v9とかが出てくるかもしれないと思うと、結構嬉しくない状態だなと思っています(ARMの事情に明るくないので適当言っています)。x86とarm以外については今回検討しなかったため、もしかしたら他にも厄介な点があるかも知れません。
2については言うまでも無く、これまではmulti stage buildによってDockerさえあればビルド出来る状態でした。しかしクロスビルドによってDockerイメージの生成とバイナリの生成を分離したことで、DockerだけでなくGoの環境が必要になってしまいました。幸いGoはインストールも簡単なので、他言語と比べると非常に楽な方ではあると思います。
buildxに対する雑感
buildx周りのコマンドは洗練されていない印象が強いです。buildx のサブコマンドは対応するリソースとアクションが分かりづらく、また未だ知見も少ないことからかなり手探りでした。一方でGitHub Actionsで使えるように用意されているactionは広く使われることを意識しているのか、かなりわかりやすく整えられていると感じました。とはいえスケールする構成にするためにはdocker manifestコマンドなどを知っていなければいけないなど、まだ発展途上な仕組みであることには違いないようです。
また、複数プラットフォームのイメージをラップトップで一度にビルドするのは計算リソースの問題から厳しいことが分かってきました。検証しているとひっきりなしにMacBook Proのファンが唸るのでかなり厳しい気持ちになってしまいました。力こそパワー、ラップトップを捨ててつよつよワークステーションを買いましょう。
結論
- 強い計算リソースを買えば問題は解決
こうすると良いよ的な情報があればどしどし寄せて頂けると幸いです。
参考
- www.docker.com
- docker manifestによる方法を「The hard way」と言っていますが、正直こっちの方がわかりやすいかつスケーラブルな仕組みにしやすいと思います。
MAASでストレージレイアウトのカスタマイズを探求したがよくわからなかった話
MAASとは
Metal as a Service の略で、Ubuntuの開発元であるCanonicalが開発している、オープンソースのベアメタルサーバ管理ソリューションです。
以下の様な機能を提供しています。
- OSのインストール自動化
- PXEブートして curtin + cloud-init でプロビジョニング
- VLAN管理
- DNSおよびDHCPの提供
- 各種Bare Metal Controller(IPMI、HP iLO、Intel AMTなど)との連携による電源管理*1
- 物理マシンのインベントリ
- KVM・LXDホストおよび仮想マシン管理
Web UIからこれらの一連の操作を行うことが出来ます。例えばAWSのWebコンソールのように、ボタンをぽちぽちしたりAPI経由で仮想マシンおよび物理マシンの構築がオンプレミスでもできるようになります。
環境
pudding@maas-master:~$ snap list | grep maas maas 2.9.2-9165-g.c3e7848d1 12555 2.9/stable canonical* - maas-cli 0.6.5 13 latest/stable canonical* -
MAASのストレージレイアウトつらい問題
2021年6月現在の最新安定版である v2.9 では、デフォルトで以下のレイアウトがサポートされています*2。
- Flat layout
- LVM layout
- bcache layout
- VMFS6 layout
- VMWare ESXiをデプロイする際に自動で選択されるモード。よく知らない。
- Blank layout
- 手動でのパーティションレイアウト作成が必要なモード。そのままではOSのインストールができない。
これ以外のレイアウトをUIから指定したい場合、MAASでCommissionしてそのマシンの構成情報を取得・UI上からデバイスやパーティションレイアウト・ファイルシステムを手動で編集するしかありません。
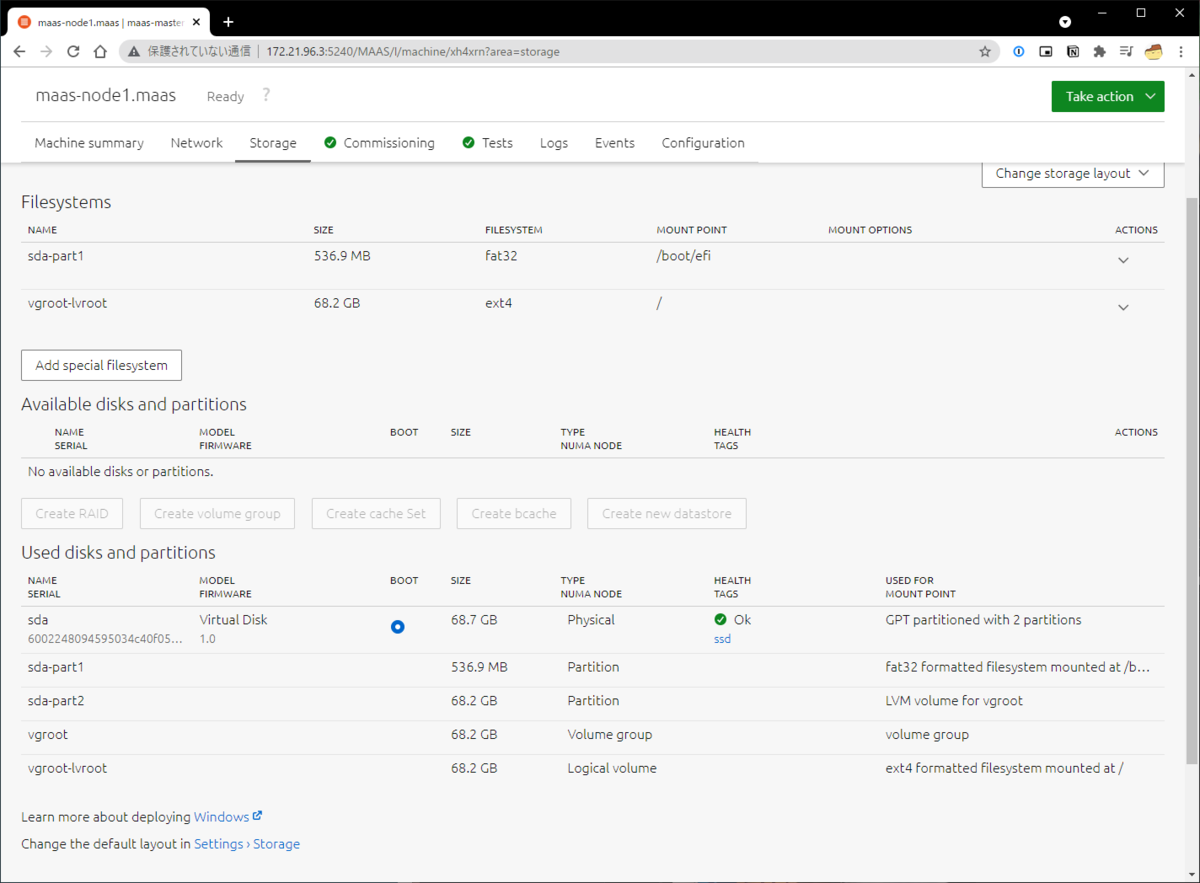
数台程度しかマシンがない一般的なご家庭ならまだしも、逸般的な誤家庭とか、企業のプロダクション環境のサーバは単一のディスクしかないシンプルな環境とはほど遠いはずです。デフォルトで用意されているストレージレイアウトはどう見ても機能不足で、一台ずつ手動設定というのはさすがに目も当てられません。
curtin
Ubuntuの有名さに対して、curtinは驚くほど知られていません。例えばQiitaで curtin を検索してみても、軽く読んだ限り明示的に利用しているのは以下の記事だけのようでした。
公式ドキュメントを見ても何ができて何を目指しているのか全然分からないというのが正直な感想でした。
curtinのconfigを抽出する
とにかく、MAASは内部的にはこのcurtinを利用してマシンのセットアップを行っています。以下のドキュメントで説明されています。
MAASは選択したストレージレイアウトに従って動的にcurtinの設定を生成し、デプロイしているようです。一度手動でストレージのレイアウトを編集してデプロイし、MAAS CLIからその設定を抜き出すことで、独自のレイアウトを再利用することができます。
$ MAAS_USER=MAASのログインユーザ名 $ MAAS_URL=MAASのURL(例:http://localhost:5240/MAAS/) # API KeyはWeb UIから入手可能 $ maas login ${MAAS_USER} ${MAAS_URL} API key (leave empty for anonymous access): # ホスト名と紐付けて目的のノードのsystem idを探す $ maas ${MAAS_USER} machines read | jq -r '.[] | .hostname + ": " + .system_id' maas-node1: xh4xrn maas-node3: qbyswd maas-node2: t3f4ba # 今回はmaas-node1のcurtin configを適当なファイルに吐く $ maas ${MAAS_USER} machine get-curtin-config xh4xrn > /tmp/curtin-config-lvm
重要なのは storage: から始まるセクションだけなので他は消してしまって良いです。以下の様なマシンでLVM layoutを選択した場合のストレージレイアウトです。
storage: config: - grub_device: true id: sda model: Virtual Disk name: sda ptable: gpt serial: 6002248094595034c40f053014e7387d type: disk wipe: superblock - device: sda flag: boot id: sda-part1 name: sda-part1 number: 1 offset: 4194304B size: 536870912B type: partition uuid: 33524d54-d698-43e5-985e-cc68b470f720 wipe: superblock - device: sda id: sda-part2 name: sda-part2 number: 2 size: 68174217216B type: partition uuid: 9d681714-39ad-42e2-a555-84f52b9cb216 wipe: superblock - devices: - sda-part2 id: vgroot name: vgroot type: lvm_volgroup uuid: 280744d7-d041-40e2-98c8-4d4810d780f2 - id: vgroot-lvroot name: lvroot size: 68170022912B type: lvm_partition volgroup: vgroot - fstype: fat32 id: sda-part1_format label: efi type: format uuid: 4314dc3b-b93a-4d9f-a0f2-68c167f6bb03 volume: sda-part1 - fstype: ext4 id: vgroot-lvroot_format label: root type: format uuid: d422bd61-cd28-473e-ad17-7e80fc51a241 volume: vgroot-lvroot - device: vgroot-lvroot_format id: vgroot-lvroot_mount path: / type: mount - device: sda-part1_format id: sda-part1_mount path: /boot/efi type: mount version: 1
公式ドキュメントを読むとおおよその意味は分かります。
この設定でmaas-node1を固定するには以下の様にします(storageセクション以外は消しておくこと)*3。
$ sudo cp /var/snap/maas/current/preseeds/curtin_userdata.sample /var/snap/maas/current/preseeds/curtin_userdata_ubuntu_amd64_generic_focal_maas-node1
$ cat /tmp/curtin-config-lvm | sudo tee -a /var/snap/maas/current/preseeds/curtin_userdata_ubuntu_amd64_generic_focal_maas-node1
抽出したconfigを流用する
現在の設定には2つつらみがあります。
- uuidやserialが指定されている
- ボリュームのサイズが指定されている
前者を解決するために、とりあえずそれらの値を全部削除します。type: partition および type: format についてはuuidが無くても動く*4ようですが、 type: disk では serial もしくは path の指定が必要なようです*5。よって以下の様にpathを指定します。
storage:
config:
- grub_device: true
id: sda
model: Virtual Disk
name: sda
ptable: gpt
- serial: 6002248094595034c40f053014e7387d
+ path: /dev/sda
type: disk
wipe: superblock
この設定はかなりハードウェアの変更に弱いです。全然良い方法とは思えませんが共通化するためにはこれくらいしか方法が無いように思われました。
後者は解決できませんでした。
https://curtin.readthedocs.io/en/latest/topics/storage.html#partition-command
Note Curtin does not adjust size values. If you specific a size that exceeds the capacity of a device then installation will fail.
このように書いてあり「残り全部」みたいな指定ができません。管理するマシンのストレージ容量の最低値を基準にすれば一応動くはず……*6。
この設定を Ubuntu 20.04 かつ amd64 なマシンのセットアップに利用するためには、ノードごとの設定と同じようにファイルを配置します。
$ sudo cp /var/snap/maas/current/preseeds/curtin_userdata.sample /var/snap/maas/current/preseeds/curtin_userdata_ubuntu_amd64_generic_focal
$ cat /tmp/curtin-config-lvm | sudo tee -a /var/snap/maas/current/preseeds/curtin_userdata_ubuntu_amd64_generic_focal
ノードごとの設定が無い場合、デフォルトの設定を無視してこのストレージレイアウトが読まれます。
疑問点
さて、全ノードが全て同容量の単一ディスクしか持っていない場合はこれでもうまくいきそうです。しかし現実には、
など様々なケースが考えられそうです。果たしてこれをプロダクション環境で利用している人たちはどうやっているんでしょうか……
ホストごとに設定を作ることは出来ますが、ホスト名のプレフィクスなどで読み込むconfigを変えるようなロジックは無さそう*7であり、
- インストールするOSのバージョン・マシンのアーキテクチャの組ごとにマシンの構成の方を固定化してしまう
- 全ホストで独自の設定ファイルを生成するようにする
のいずれかの対策をとらなければいけないように思われます。
まとめ
おうちでベアメタルクラウドをやる第一歩としてMAASでPoCしていたところ、ストレージ周りの工夫が必要なことが判明したため少し調べました。
現状では一度手動で設定し、その設定を流用することで以降独自のストレージレイアウトでプロビジョニングできそうです。ただしノードごとに構成が揃っていることが必要そうです。
これをプロダクション環境で使っている人たち、どうしているんですかおしえてください 🙏
参考
*1:いずれもそのマシンがサポートしていない場合、手動で電源をオンにしたりする必要があります
*3:https://maas.io/docs/snap/2.9/ui/custom-machine-setup#heading--template-naming
*4:そもそもpartitionのドキュメントには uuid の項目がありません。このパラメータがどう使われているのかは不明です。 https://curtin.readthedocs.io/en/latest/topics/storage.html#partition-command
*5:https://curtin.readthedocs.io/en/latest/topics/storage.html#disk-command
*6:使えない領域が出来ます
*7:https://github.com/maas/maas/blob/1aa6276c0b6d7d702f1ed3036fd11d30e879c285/src/maasserver/preseed.py#L614
これからコーヒー趣味を始める人に伝えたいこと3選
tl; dr
- コーヒー器具の○杯用は小さいコーヒーカップ換算なのでマグカップで飲むなら信用するな
- 余談:コーヒーサーバはオールガラスが洗いやすくておすすめ
- 沸きたての熱湯でドリップするな、少し冷ませ
- サーカスコーヒーはいいぞ
はじめに
この記事はコーヒーが趣味な筆者が偏見と経験だけを元に言いたいことを書いた物です。決して空いていたあくあたん工房アドベントカレンダー10日目の枠を埋めるためではありません*1。
最近身の周りに家でコーヒーを家でドリップして飲む人が増えてきたような気がします。とても嬉しいので皆さんどんどん開拓して僕に色々教えて下さい。
この記事では始めたばかりの頃に引っかかりがち・やりがちのことについて軽く触れます。もちろん好みの部分もあるので、自分の手と舌と鼻を一番信用して下さい。なお、本記事で色んなものを紹介していますが、筆者にアフィリエイト収入等一切入りませんので安心して(?)ご覧下さい。
コーヒー器具の「○杯用」という表記
僕は昔からこの表記が好きではないのですが、コーヒーをドリップするための器具にはどの程度の量をいれるのに良いか、という指標として「○杯用」などの表記が採用されています。大抵は1〜2杯用、もしくは3〜4杯用が一般的です。ところで、この「1杯」とは具体的に何mlに相当するんでしょうか?
カップ一杯分(約140cc)
1杯 120 ml
HARIOのドリッパーV60の説明書き https://www.hario.com/manual_pdf/VD.pdf
一杯分(120ml)
どうも120〜140mlくらいのようです。ここで我が家にあるコーヒーカップとマグカップを見てみましょう。

高さは約半分というところです。口の広さは同じくらいですね。


小さく見えるコーヒーカップですが、僕は普段これに160~170ml入れて飲んでいます*2。既に120mlを大きく超えていますね……マグカップのときは230〜250mlくらい入れているため、だいたいマグカップ一杯が世に言う「2杯分」くらいに相当します。つまり、1~2杯分の器具だと実はマグカップ1杯分にしかならない可能性があり、来客対応などが難しくなる可能性があります。大は小を兼ねるということで、とりあえず3~4杯用のものを買っておくのが丸いと思います。
ところで1杯120mlという根拠はなんなんでしょうね……エスプレッソなどを飲むデミタスカップとしては120mlは多すぎますし、レギュラーコーヒーを飲む用としてはいささか量が少ない気がします。軽く調べてみてもコーヒーカップは満水時200mlくらい入るのが主流なように感じます。120mlだとかなり寂しい量になりそうですね。
余談:コーヒーサーバはオールガラス製が洗いやすい
コーヒーサーバとは、ドリッパーを使って抽出したコーヒーを一時的に入れておくポットです。Amazonなどで安いコーヒーサーバを探しているとだいたい以下の様な物がヒットすると思います。

とても安くて入手性も良く、持ち手が熱くならないなど良いこともあるんですが、とにかく洗いづらいし乾かしづらい。
このプラスチックの部品とガラスの隙間に汚れや洗剤が溜まったり、そこだけ乾かなくてドリップしたときに温められた空気に押し出されて出てきたりします。
長年これが個人的に悩みで、しかしなかなか頑丈で壊れないので買い換えられずにいました。去年あるときついに割ってしまい、どうにかこのプラスチックの持ち手を避けようと色々探していたら各社それなりにオールガラス製のコーヒーサーバを出していることが分かりました。
僕が持っているのは以下のコーヒーサーバです*3 www.amazon.co.jp

オールガラス製で心配していたのは持ち手が折れてしまうとか熱くなってしまうとかですが、今のところ特にそういう問題は出ていません。たぶんこの持ち手が折れるようなときにはコーヒーサーバごと割れるので、持ち手がプラ製でも変わらんなというのが僕の感想です。とにかく洗いやすくなったし見た目もなんかオシャレなのでオススメです。
ドリップするときの温度
コーヒーの抽出というのは非常に難しく、かつ繊細な工程です。そしてドリップにおいて重要な要素の一つが湯温です。コーヒーのドリップ方法について調べると分かりますが、だいたい90℃!とか85℃!とかみんな言うことがバラバラで統一的な見解がありません。それは当たり前で、個人の好みや抽出器具、豆、煎り具合など多数の要素があるうちの一つの要素に過ぎないため、他の要素との兼ね合いで変わるためです。
一般に湯温が高ければ苦みが強い味になります。それに加えてえぐみや渋みの様な味も強くなります*4。多少まともな豆を買ってコーヒーを抽出する際にあまりに高い湯温にしてしまうと強い苦みや渋みが出てしまい、あれ?なんか安豆と変わらないのでは……?となりがちです。
T-falなどに代表される湯沸かし器を使ってお湯を沸かし、それを使ってドリップしている人が多いのではないでしょうか。最近は温度調節機能がついたものもありますが、多くの場合は沸騰させる機能しか無いはずです。この場合、完全に沸いたお湯をすぐ使うと100℃近いため、前述したように余計な成分を抽出してしまい本来ある豊かな香りやコクを損ないやすいです。
ドリップポットで少し冷ます
ドリップポットとかドリップケトルとかそういう呼び方をする道具があります。

これにはドリップ時にお湯を注ぎやすくするだけで無く、湯温を適度に下げるという役割もあります。あと見た目がオシャレになってなんかカッコイイ。
キッチン用の温度計が1000円台で買えるので、
- 電気ケトルからドリップポットに注ぐ
- 適当に85℃くらいに調整してドリップ
- 苦みが濃い→次回から温度を少し下げる
苦みが薄い→次回から温度を少し上げる
こんな感じで良い具合の所を探ってみて下さい。
どこで豆を買うか

コーヒー豆はいろんなところで売っています。スーパーなどで売られるとてもリーズナブルな豆から、スターバックスやカルディなどのようなちょっとお洒落な雰囲気を漂わせた豆、専門店のお高い豆まで幅が広いです。
個人的にはやはり専門店に行って、その香りに触れて選んで欲しいなと思いますが、そうは言っても世間は大コロナ時代。やはり家から頼めるオンラインショップで済ませたいところ……。
というわけで筆者のおすすめコーヒー豆ショップを紹介します。
銀行振り込みしかありませんし、送料もかかりますが、一度は試して欲しいと思っています。初めて注文する方は以下の送料お得セットで少量試してみるのはいかがでしょうか。
挽いてもらわず豆のままであれば、ジップロックなどで密閉して冷凍庫で3週間〜4週間くらいもちます。ミルで挽くときに解凍なども不要です。是非お試しあれ。
まとめ
アドベントカレンダーの穴埋め筆者の丁寧なくらしの紹介いかがでしたでしょうか。 コロナで心がすさみがちな日々、コーヒーでほっと一息つくのは良い物ですよ。
明日のあくあたん工房アドベントカレンダーもご期待ください。