coreutilsのlnでのシンボリックリンクの更新はアトミックになっている気がする
シンボリックリンクの更新におけるatomicity
シンボリックリンクをアトミックに更新するには、単にln -snf ではダメだという記事を昔読んでずっとそうなんだと思っていた。
この記事ではstraceでlnの挙動を追いかけ、シンボリックリンクの更新には unlink してから symlink しているのでアトミックではないと書かれていた。
StackOverflowなどでもこのような回答は多く見られた。
unix - Can you change what a symlink points to after it is created? - Stack Overflow
web deployment - atomic way of deploying website updates? - Stack Overflow
やってみた
Ubuntu 22.04 LTS
$ uname -r 5.15.0-91-generic $ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 22.04.3 LTS Release: 22.04 Codename: jammy
ふとしたときにlnのstraceを取る機会があり、見ていたところ思っていたのと違う挙動になっていた。 適当なディレクトリを作成し、その中で以下の様なコマンドを実行してみた。
echo "hello old" > hello.txt strace ln -sf hello.txt hello.sym
straceの結果を見ると、このときは単に symlinkat が呼ばれている。
... 省略 ...
symlinkat("hello.txt", AT_FDCWD, "hello.sym") = 0
... 省略 ...
次に、新しいファイルでこれを上書きしてみる。
echo "hello new" > hello.new strace ln -sf hello.new hello.sym
hello.sym には既に既存のリンクがあるため、symlinkat をしようとして EEXISTS で失敗し、最終的に乱数名のsymlinkを作った後renameしているようだ。
... 省略 ...
symlinkat("hello.new", AT_FDCWD, "hello.sym") = -1 EEXIST (File exists)
openat(AT_FDCWD, "hello.sym", O_RDONLY|O_PATH|O_DIRECTORY) = -1 ENOTDIR (Not a directory)
newfstatat(AT_FDCWD, "hello.sym", {st_mode=S_IFLNK|0777, st_size=9, ...}, AT_SYMLINK_NOFOLLOW) = 0
newfstatat(AT_FDCWD, "hello.new", {st_mode=S_IFREG|0664, st_size=10, ...}, 0) = 0
openat(AT_FDCWD, "/dev/urandom", O_RDONLY) = 3
read(3, "\37f\22\377\241\351", 6) = 6
close(3) = 0
getpid() = 4322
getppid() = 4319
getuid() = 1000
getgid() = 1000
symlinkat("hello.new", AT_FDCWD, "CurXXqPD") = 0
renameat(AT_FDCWD, "CurXXqPD", AT_FDCWD, "hello.sym") = 0
... 省略 ...
この挙動は、適当な名前のsymlinkを作ってからmvする方法と全く同じ事をやっているように見える。 実際に先のページに書いてあるようなテストコードを実行してみてもエラーになることは無かった。
$ cat << EOF > ln.sh
#!/bin/sh
echo test1 > src1
echo test2 > src2
while :
do
ln -snf src1 dst
ln -snf src2 dst
done
EOF
$ chmod +x ./ln.sh
$ cat << EOF > cat.sh
#!/bin/sh
while :
do
cat dst
done
EOF
$ chmod +x ./cat.sh
$ ./ln.sh
↓別のシェルで実行
$ ./cat.sh
macOS 14
macOSには strace がなく、代わりに dtruss というコマンドが使えるらしい*1。なお、 ln コマンドのシステムコールをトレースするためにはSIPによる保護を無効化しなければならなかった。
SIPを無効化せず、codesign コマンドで署名を削除することで dtruss が使えるようになるというハックを見つけた*2が、少なくとも自分の環境(M1 Pro macOS 14.1)ではエラーになった。
$ cp /bin/ln ./ $ sudo codesign --remove-signature ./ln $ sudo dtruss -deflo ./ln -sf hello.txt hello.sym dtrace: system integrity protection is on, some features will not be available dtrace: failed to execute ./ln: Could not create symbolicator for task
一時的にSIPを無効にしてやってみた結果:
$ echo "hello old" > hello.old
$ sudo dtruss -deflo ln -sf hello.old hello.sym
... 省略 ...
1883/0x385d: 1317 3 2 lstat64("hello.sym\0", 0x16D91A370, 0x0) = -1 Err#2
1883/0x385d: 1318 0 0 stat64("hello.sym\0", 0x16D91A370, 0x0) = -1 Err#2
1883/0x385d: 1319 1 0 lstat64("hello.sym\0", 0x16D91A370, 0x0) = -1 Err#2
1883/0x385d: 1460 140 140 symlink("hello.old\0", "hello.sym\0") = 0 0
$ echo "hello new" > hello.new
$ sudo dtruss -deflo ln -sf hello.new hello.sym
... 省略 ...
2177/0x41df: 1200 10 9 lstat64("hello.sym\0", 0x16D686370, 0x0) = 0 0
2177/0x41df: 1206 5 5 stat64("hello.sym\0", 0x16D686370, 0x0) = 0 0
2177/0x41df: 1208 2 1 lstat64("hello.sym\0", 0x16D686370, 0x0) = 0 0
2177/0x41df: 1276 68 68 unlink("hello.sym\0", 0x0, 0x0) = 0 0
2177/0x41df: 1305 63 28 symlink("hello.new\0", "hello.sym\0") = 0 0
よってmacOSの組み込みlnコマンドではアトミックになっていない。実際にあの単純なテストコマンドを実行すると以下の様にエラーになるケースが確認できた。
$ ./cat.sh ... 省略 ... test1 test2 test1 test1 cat: dst: No such file or directory test2 test1 test2 cat: dst: No such file or directory cat: dst: No such file or directory ^C
macOSではHomebrew等を使ってGNU coreutilsをインストールして使うことができる。
$ brew install coreutils
なおこのとき ln ではなく gln のように g というプレフィクスを付けて呼ぶ*3。
こちらは当然symlinkatした後にrenameatしており問題は発生しない。
$ sudo dtruss -deflo gln -sf hello.new hello.sym
... 省略 ...
21550/0x11e09: 1837 15 15 symlinkat("hello.txt\0", 0xFFFFFFFFFFFFFFFE, "hello.sym\0") = -1 Err#17
21550/0x11e09: 1844 7 6 openat(0xFFFFFFFFFFFFFFFE, "hello.sym\0", 0x40100000, 0x0) = -1 Err#20
21550/0x11e09: 1849 3 3 fstatat64(0xFFFFFFFFFFFFFFFE, 0x16DD8BA6A, 0x16DD8B3F8) = 0 0
21550/0x11e09: 1851 1 1 stat64("hello.txt\0", 0x16DD8B488, 0x0) = 0 0
21550/0x11e09: 1862 10 10 open("/dev/urandom\0", 0x1000004, 0x0) = 3 0
21550/0x11e09: 1863 1 1 read(0x3, "?\275L\205Gm\321\225@\004\0", 0x8) = 8 0
21550/0x11e09: 1953 90 89 symlinkat("hello.txt\0", 0xFFFFFFFFFFFFFFFE, "CuXBf0rC\0") = 0 0
21550/0x11e09: 2032 79 78 renameat(0xFFFFFFFFFFFFFFFE, "CuXBf0rC\0", 0xFFFFFFFFFFFFFFFE, "hello.sym\0") = 0 0
... 省略 ...
いつ変わった?
2017年のこのあたりのコミットで挙動が変わったのだろうか……?
このコミットはv8.27から含まれていそう。
If the file B already exists, commands like 'ln -f A B' and 'cp -fl A B' no longer remove B before creating the new link. That is, there is no longer a brief moment when B does not exist.
このあたりが該当する……?少なくともここ最近のcoreutilsが入っている環境なら問題無さそうだ。
まとめ
- coreutils v8.27以降の
lnコマンドは既存のシンボリックリンクを更新する際、乱数名でsymlinkatした後にrenameatしていそう - 少なくとも最近リリースされたLinuxディストリビューションではシンボリックリンクの更新は単に
ln -snfとかを使っても問題無さそう - macOS組み込みの
lnコマンドはunlinkしてsymlinkしているのでダメそう
何か落とし穴あったら教えてください。
ソフトウェアエンジニア4年目
はじめに
これはあくあたん工房 Advent Calendar 2023 10日目の記事です。
あくあたん工房という団体を設立してから6回目のAdvent Calendarらしいです。なんだかんだ長く続いていて正直ただただ驚いています。後輩たちの努力が凄い。
もうすぐ社会人5年目というところで、自分の仕事とキャリアに関する所感を書いておこうかなと思っています。それなりにちゃんと仕事をし、それなりに大きなタスクを任せられるようになり、社内でのプレゼンスも徐々に上がってきたのでやっていることの方向性は大きく間違っていないんじゃないかなと思っています。 ソフトウェアエンジニアとしてキャリアを歩んでいくということはおそらく多くの学生にとって未知であり、何かの参考になると嬉しいです。
TL; DR
- 知り合いは多い方が良いよ
- 意見や質問は積極的にしようね
- チームを大事にしようね
お仕事
探せば普通に所属とかわかるけどなんとなく濁しています。
- Web系企業(新卒入社)
- SREとかインフラエンジニアとかそういう感じ
- めちゃくちゃコードは書いている
クラウドを一切触らないわけではないですが主にオンプレが主戦場です。
バックエンド・ミドルウェアあたりから下、物理より上くらいの基本的にお客様から直接的には見えないレイヤーを取り扱っています。
この職自体は1年目から続けていて、2年目直前あたりから比較的大きめのプロジェクトに関わり始めました。いわゆるインフラ基盤の刷新というやつです。 日々レガシーなコード、知らない仕様、どんどんやってくる障害と戦っています。
今のポジション
おおよそ中の上くらいのミドルエンジニアと言って良いでしょう*1。そろそろシニア名乗って良いでしょと思っているので、そういう感じでマネージャに掛け合っているところです。
チームはまだ小さく、スタッフレベル*2のエンジニア(以降チームリーダー)の下で良く言えばナンバー2として働いています。元々はほぼ2人体制でしたが、ありがたいことにここ2年で倍以上になりチーム感が出てきたところです。
部署はもう少し大きく数十人規模で、それらのメンバーがまとまって現在のサービスの運用を担っています。
お仕事内容もう少し詳しく
- 既存のサービスおよび基盤の運用・メンテ
- 深夜対応などもする。複数チームによる週単位のローテーション制。
- 既存のサービスの基盤移行に伴う検討・設計・実装・運用・メンテ
- 対象は全てではない。複数のチームが同時に動いていて、色々なサービスの移行が並行して行われている。
理想的なDevOpsにはまだ遠く、自分が書いたわけではないアプリケーションの運用をしていて、問題が起きたから見てくれとエスカされるみたいなこともメインの業務の一つです。逆にこういうことが起きているがわからん助けてくれと開発しているチームにエスカするなどもしています。
現在の基盤もまだまだ使っているため、その改善なども行います。デプロイを早くしたり、パフォーマンス問題を解決したり、レジリエンスを向上させたりなどです。
既存のサービスの基盤移行にはお客様から直接見えるアプリケーションの開発チーム始め様々なチームが関与します。それらのチームが顔を突き合わせて議論する場に出席し、主にインフラ側からの意見・SREとしての意見を出しています。ここで方針を決め、各チームが実装し、実際に移行のオペレーションを行います。
移行は単純に載せ替えればよいという物ではなく、歴史的経緯により複雑に絡み合った毛玉からセーターを作るようなもので、日々どうにか着られるセーターになるようにみんなで糸を引っ張ったり切ったり結んだりしています。
その過程で流用が難しいものをフルスクラッチで書き直したり、既存のコードに手を入れたりします。ここで主にコードを書いていて、チームメンバー(リーダー含む)にコードをレビューされたり逆にレビューしたりしています。
だいぶぼかして書きましたが、要するに非常に不確実性の高いタスクとずっと向き合っています。正解はなく、先は長く、しかし長引かせ続けて苦しくなるのは自分なので手短に行わなければいけません。
今後のキャリアに関する所感
何も分からん。
何も分からんけど、とりあえずしばらくは今の延長戦で十分戦えるなという感じです。問題はそこから頭一つ抜けるために何が必要かです。 あまりにも何も分からんので、今年は何かの参考になれば良いなと思ってスタッフエンジニア本を読んだりしました*3。
各社のエンジニアリング組織の文化、その中のポジション、必要とされる仕事には様々なものがあり、あまりスタッフエンジニアはこういうことをするといった画一的な定義があるわけではないことが分かったのは収穫でした。
自分が社内でのプレゼンスを増していったとき、そこで必要だと考え認められた仕事が結果として何らかのポジションを得るんじゃないかなという気持ちになってきています。
キャリアのために意識してやっていること
マネージャになるにせよ、スタッフエンジニアを目指していくにせよ、IC*4としてめきめきやっていくにせよ、共通して重要なのはソフトスキルです。主にそこに対して自分がやっていることを書きます。
技術面では普通にやっているだけなので特筆することが思い浮かびませんでした。特にあくあたん工房に居るようなメンバーならあんまり心配することは無いと思います。
どこからが意識的にやっていて、どこからが無意識的にやっているかと問われると難しいところですが、意図を述べることができる場合は意識的にやっているということにします。
他の人の手助けをする
例えばKubernetesを使っていてこういうことがしたいがエラーが出る、やり方が分からない、これってできるのかな?みたいな投稿を見かけたら意見を述べるようにしています。これは同じチームに限らず、他チーム・他部署に関しても同様です。特にアプリケーションを開発しているメンバーが下回りで困っているときは積極的に関与しています。
他にも最近ジョインしたメンバーが分からないと言っていたらドキュメントやコードへの参照を教えたり、他チームから問い合わせが来たら早めの回答を心がけたりしています。
これは単純に会社全体としてその方が効率が良いというだけではなく、自分の信頼感を上げるための施策の一つと考えています。会社というのはそれなりの人数が居るので、埋もれると一生認知してもらえません。自分の名前を売ること、その名前を良い意味で覚えてもらうことを意識しています。
意見を述べる・質問をする
ずっと横柄な態度取ってるとただのヤバイやつですが、何も言わずにただただ従ってるだけというのはキャリアがどんどん閉ざされると思っています。ある程度の厚かましさは必要だと思っていて、これってどうなん知らんけどとか、なぜそうなってるんですかとかを例え他チーム・他部署のエンジニアにでもぽいぽい投げるようにしています。
多くの人は出来れば他の人が決めてほしいと思っているし、意見を出す最初の一人になりたくないと思っている節があります。そのため、意見を求められたときに場が沈黙して終わりになる場面を度々見かけます。ただ意見を出すだけ質問するだけで議論が活発になる面があり、声を上げる上げないの間には大きな差があります。
これも同様に自分の認知度を上げるための施策の一つであり、同時に自分のやりたい仕事に方向を近づけるための努力でもあります。どうせ同じような仕事するなら自分のやりたい仕事したいですよね。
仕事を任せられる人を増やす
自分一人で仕事をするには限界があります。自分がある程度整理した仕事を処理してくれる人、なんなら不確実性の高いタスクを投げたときに自分の代わりに整理して実行までやってくれる人が居ないと、どこかで処理出来るタスク量が頭打ちします。
当初から人数の少ないチームだったので、人を入れなければいずれ詰むという危機感がありました。工数的にはかなり厳しかったのですが、新人の体験的な受け入れ・学生との面談・インターンシップの開催等は必須であると考え積極的に手を上げるようにしていました。最終的に人を採用できチームに迎え入れられたのはマネージャや他の社員のおかげでもあり、人が足りない・受け入れる用意はあると訴えてきた自分の努力のおかげでもあったと考えています。
自チームに引き込む以外に、他のチームに依頼できる関係を構築しておくのも重要だと思っています。普通に仕事をしていると、自チームの外とは会議の場くらいでしか会わず、気軽にメンションしたりはなかなかハードルが高くなりがちです*5。社内の勉強会、雑談、イベントに顔を出してある程度緩和を試みています。まだここは試行錯誤できる余地が大きいなと思っています。
多様な情報にアンテナを張る
これは元々趣味なので、それほど昔から傾向は変わっていないかなと思っています。技術的なトークが出来る人が増えたり、専門ほどではないにせよ概念を理解していることで応用が利いたり、よいことがたくさん有ります。
自分は主にFeedlyで色んなRSSを購読し、Twitterで軽く話題になっているものに目を通して、Notionに印象に残った物をクリップしてストックしています。

ただ、年々これが厳しくなってきているように感じており、今後の情報収集にはあまり期待できないかもなぁと思っています。以下は直近一年での自分の情報収集の変遷です。
- QiitaのトレンドのRSS購読をやめた
- はてブのトレンドを追うのをやめた
- 特定の個人や企業のブログのRSSを個別登録するようになった
- Techfeed登録してみたけどむしろノイズが増えたので見るのを辞めた
- Twitterが使い物にならなくなってきてBlueskyに移った
- まだ時折見ているがおすすめタブが精神に良くなく封印しがち
ちゃんとした人脈を持ち、情報をキュレーションして伝えてくれる人をたくさん知っている人が強くなるなと思っていて、あくあたん工房のメンバーがそういう人脈形成の一つになれば嬉しいなと思っています。
次にやろうと思っていること
やろうと思っているけど出来ていないとか、まだ足りていないなと思っていることです。
メンバーの成果をアピールする
今居るチームにおいて、得られた成果は自分が動いて出したものだけではありません。チームメンバーが手を動かして書いてくれたコード、ドキュメント、障害調査報告……など色々なものがチームの成果として存在しています。
チームの中で特定個人が目立っていると、成果がその人に吸引されがちです。その結果、新しい仕事がどんどんその人に集中してしまうことが起きがちです。ここでその人が正しく仕事を割り振ることも大事ですが、それを常態化してしまうとその人がチームを抜けた/休んだときに他チームとの折衝を上手くやれる人がおらずチームが機能不全になってしまうという問題があります。
チームメンバーが多くなってきたら別ですが、今くらいの規模なら全員がお互いの代わりを務められるくらいでありたいものです。来年はメンバーの成果を積極的に紹介する場を設け、社内に対してアピールして自分以外にもこういう優秀なメンバーが居ますよ覚えてねと言っていきたいと思っています。
チームに入りやすく、そして出やすくする
まだ人を増やしたいです。そして逆に、今のチームである程度経験を積んだ人が他のチームへ移動したり、他のチームを兼務したりできるようにしたいと思っています。
これは「仕事を任せられる人を増やす」にも繋がってくるのですが、色んなチームに知り合いがいた方が基本的には都合がよいです。そういう意味ではしばらく仕事を共にしたチームメイトが別チームに居るというのは、とても仕事を進めやすくなります。メンバーが「{{ 任意のチーム外で扱っている事柄 }} にも興味がある」と言ったときにそれをサポートできる体制でありたいと思っています。
人の出入りが増えるということは、チームの暗黙的なコンテクストや知識が失われがちになってしまう可能性も高めます。特にインフラ基盤の刷新みたいなドラスティックな変更が入る時期ではなおさらです。当たり前ですがちゃんと資料を残すこと、オンボーディングの道筋を示すこと、その他いろいろをちゃんとやろうと思っています*6。
終わりに
みんながつよつよエンジニアになって、お仕事とか美味しい食事を恵んでくれると良いなと思ってこの記事を書いています。
つよつよエンジニアになる方法は、技術的に突き抜ける以外にも色々あります。社内の色んなところで幅を効かせて自分に有利になるよう仕事を進めていきましょう。
*1:うちではあまり明確にあなたはこういうレベルです、みたいなものは示されません。実際の給与評価とこういう仕事を期待していますというマネージャからのコメント・会社が示す大まかなレンジを見て自分の立ち位置を言っています。
*2:スタッフエンジニアとは、おおよそエンジニアの最上級職と言って良いです。ただし内情は様々であり、人によって大きく異なる仕事をしている可能性があります。テックリードやアーキテクトなどのポジションは、スタッフエンジニアの一つの形態と言えるでしょう。
*3:買って読み始めてから知っている人がインタビューに出ていることを知って驚きました
*4:Individual Contributor。チームや人のマネジメントをしない、専門職としてのソフトウェアエンジニア。
*5:ハードルが高いだけなので僕は目をつむって送信ボタンを押します
*6:今のチームでは中途のメンバーからのアドバイスで、今年からちゃんと大きめの実装の前にdesign docを書き始めました。書いた資料を元にチームメンバーで合意をとりつつ、お互いの分かっていないところを補完し合えているのではないかなと思っています。
ISUCON優勝したくてGrafana Cloudで分析基盤を整えた
去年のnonyleneくんのブログを読んだ僕の、一年越しの回答です。
ISUCON13に参加し、最高107000点くらい106457点をマークしましたがfailしたチーム ツナ缶です。来年は優勝します。
公式から全チームのスコアおよび結果が出ました。failしていなければ最低でも16位くらいだったと思われ、大変無念です。 ISUCON13 受賞チームおよび全チームスコア : ISUCON公式Blog
今回は割とよい分析基盤が出来たかなと思ったので紹介します。
メンバー紹介:
Grafana Cloudとは
詳しくは↓を参照
2ヶ月ほど前に家の監視基盤をGrafana Cloudに移したのは、ISUCONに向けた素振りをするためでもありました。Grafana Cloudで基盤を作ると良さそうと感じたのは主に以下の点でした。
- ログの閲覧ができる
- ログをパースしてメトリクスとして集計して可視化できる
- メトリクスを送信することでサーバの負荷状況を同じプラットフォームで可視化できる
- Goのpprofに対応した継続的プロファイリングにより、フレームグラフを同じプラットフォームで閲覧できる
- 上記を全て単一のAgentでアプリにほとんど手を入れずに実現できる←ここ重要
他にも仕事でGrafanaやPrometheus、Lokiとは仲良くしているので、これらを使った解析基盤は自分の知見が活かせるのでは(そして仕事でも使えるのでは)という思惑がありました。
できたもの
APIエンドポイントごとの解析

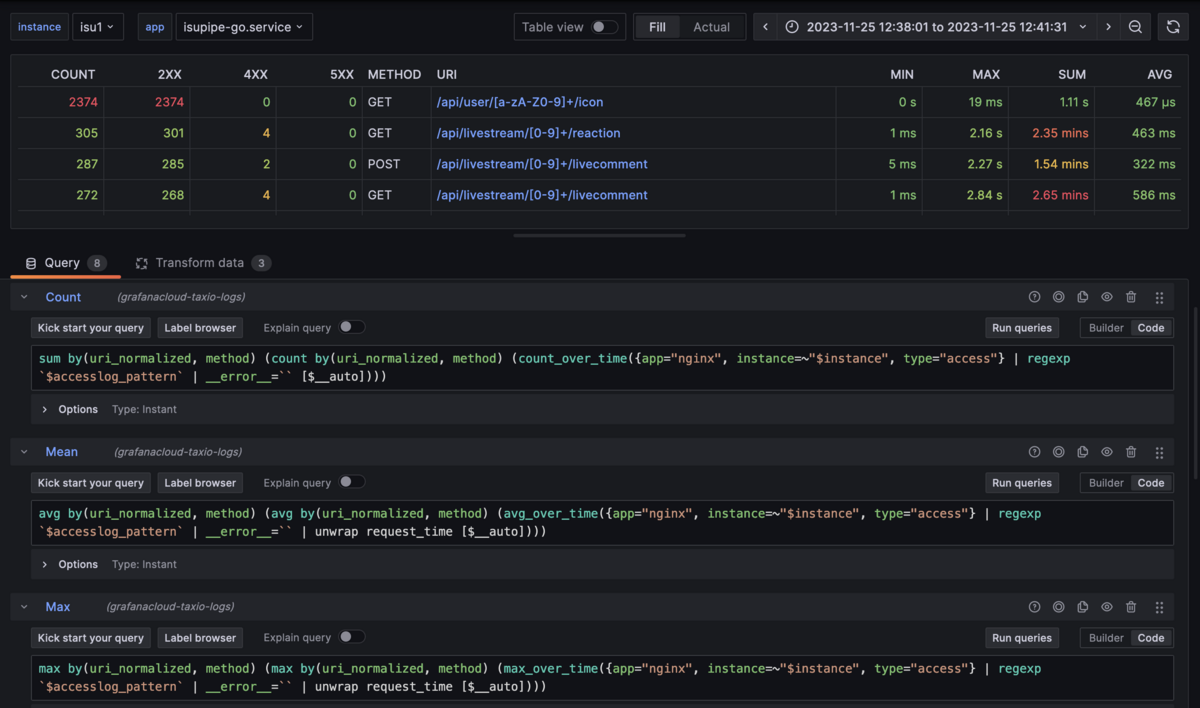
alp相当の解析ができるダッシュボードです。nginxのアクセスログをパースしてAPIエンドポイント・メソッド・レスポンスタイムの情報を頑張って組み立てています。各テーブルヘッダをクリックすることでインタラクティブにソートできるので、見たい人が見たい順に並べ直すことができます。
各URIはリンクになっており、各エンドポイントごとの詳細を別ダッシュボードで閲覧できるようになっています。

これらは全てグラフや右上の日時指定ボタンから指定日時のデータを見ることができるため、何時頃の結果、などを解析することも可能です*1
ログの閲覧・検索

時間範囲を指定して、アプリケーションやnginxのログを一つの画面で横断検索できるようにしました。ページ上部のドロップダウンメニューから見るインスタンス(全てまとめてみることも可)を、検索ボックスに任意文字列を入れて絞り込みなどができるようになっています。これらは自分はベンチマークのfail時などによく確認していました。
またエンドポイントごとの詳細画面では、エンドポイントの正規表現を使ってログをフィルタし、特定のエンドポイントのアクセスログだけを引っ張って来るなどもしていました。

MySQLでスロークエリログを有効化した場合、それも収集するようにしていました。これの数はかなり膨大で結構大変な事になっていたと思います。

指定した時間範囲で指定した秒数以上かかったクエリを表示することができます*2。ロック時間などで並び替えることも出来るようになっています。
インスタンスの負荷状況の可視化
各インスタンスではNode Exporterが動作しており*3、各ホストの状況のメトリクスを送っていました。今回は15秒に一回送信することにしていましたが、もう少し解像度が高い方がISUCONという競技では使いやすかったなと思います。

フレームグラフの表示
Grafana LabsがPyroscopeを買収したことにより実現した機能です。Grafana Agentが定期的に /debug/pprof/profile などを叩くことで、Grafana Cloudへこれらのプロファイリングデータを送信して可視化しています。

各関数にフォーカスして拡大することもでき、検索ボックスから特定の関数を調べることも可能です。go tool pprof を使って閲覧するのと変わらないような使い勝手で、しかもこちらが実施することは最初のGrafana Agentのセットアップと、Goアプリケーションでのpprof対応だけでした。セットアップはAnsibleで自動化済み、pprof対応はlabstack/echoでは依存足して1行書き足すだけだったので、ほぼ労力ゼロでこれが使えるのはかなり良いと思いました。
ログ・メトリクス・プロファイルが全て単一のプラットフォームで見れるため、他のツールの使い方を覚えたりログインを使い分ける必要がありません。また、当日に追加で行った変更は以下のような、Grafana Cloudを用いなくてもやっているいつものことだけです。
これらの対応を全て終えてISUCON本番で完全に動作し始め、ベンチマーク結果を解析出来るようになったのはおおよそ競技開始から40分後くらいでした。その間もtaxioにはマニュアルの読み込みやUIを触って理解を深めてもらうなどをやってもらっており、初動としてはそこまで悪くないかなと思っています。
さらに、そこから先で解析基盤に手を入れることはほとんどありませんでした。撤退も単にGrafana Agentを消す、pprof対応を消す、ログを出さないようにするだけで良いので非常に簡単でした。
構築編
Grafana CloudはSaaSなので、自分でセルフホストする必要がありません。収集対象のインスタンスにエージェントを入れるだけで使えます。
Grafana Agent Flowのインストール
Grafana Cloudへのログやメトリクス、プロファイルデータの送信にはGrafana Agentというエージェントを利用します。これはstatic mode(YAMLで設定を書ける)とflow mode(HCLみたいなriverという設定言語で書ける)の2種類のモードがありますが、プロファイルデータを送れるのがflow modeだけなので今回はflow modeを使います。
GitHub Releasesでdebパッケージが公開されているので単にこれをダウンロードしてきて各ホストに入れます。自分はAnsibleで全ホストにサクッと入れられるようにしておきました。
また、送信に必要なのでGrafana CloudのAPIキーを各ホストに撒いておきます。適当なところにファイルに書いて置いておきました。Grafana CloudではAPIキーのExpire dateを設定できるので、翌日とかにしておくと安心です。
メトリクスを収集する
flow modeではriverで設定ファイルを書くのですが、これはモジュール化出来るようになっています。今回は以下の様なモジュールを書いていました。
// このモジュールが取る引数を宣言できる。 argument "write_to" { comment = "remote write target" } // Node Exporterの設定をする prometheus.exporter.unix "default" { include_exporter_metrics = false // ISUCONではそこまで細かいメトリクスは要らないので適当に set_collectors = [ "cpu", "diskstats", "filefd", "filesystem", "loadavg", "meminfo", "netclass", "netdev", "vmstat", "sockstat", ] filesystem { fs_types_exclude = "^(autofs|binfmt_misc|bpf|cgroup2?|configfs|debugfs|devpts|devtmpfs|tmpfs|fusectl|hugetlbfs|iso9660|mqueue|nsfs|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|selinuxfs|squashfs|sysfs|tracefs)$" } netclass { ignored_devices = "^(veth.*|cali.*|[a-f0-9]{15})$" } netdev { device_exclude = "^(veth.*|cali.*|[a-f0-9]{15})$" } } // 設定したNode Exporterからメトリクスをスクレイプする設定 prometheus.scrape "unix" { targets = prometheus.exporter.unix.default.targets // このモジュールの引数で渡された書き込み先に渡す forward_to = [argument.write_to.value] scrape_interval = "15s" }
このモジュールを使う側では、以下の様に宣言するだけです。
// Grafana CloudのAPI Keyを書いておくファイル local.file "api_key" { filename = "/etc/grafana-agent-api-key" is_secret = true } // Grafana Cloudの書き込み先の設定 prometheus.remote_write "grafanacloud" { endpoint { url = "REMOTE WRITE URL" basic_auth { username = "BASIC AUTH USER" password = local.file.api_key.content } } } // ラベルを書き換える prometheus.relabel "replace_instance" { forward_to = [prometheus.remote_write.grafanacloud.receiver] rule { action = "replace" target_label = "instance" // Ansibleでここを各ホストごとの識別名に置き換えていた replacement = "{{ inventory_hostname }}" } } module.file "nodeexporter" { // 先ほどのモジュールまでのファイルパス filename = "/etc/grafana-agent/rivers/nodeexporter.river" arguments { write_to = prometheus.relabel.replace_instance.receiver } }
ログを収集する
ISUCONではログの収集パターンは主に2つだと考えていました。
- journaldのログ(
journalctl -u ~~などで見る物) - ローカルにあるファイルに書かれるログ
Grafana Agentではどちらも対応可能です。まずはjournal logの収集から。
argument "write_to" { comment = "Loki remote write url" } loki.relabel "journallog" { // forward_toはloki.source.journal側で指定するので記述しない forward_to = [] // 書き換えのルールの指定。 // `__` から始まるラベルは送信時にドロップされるので必要なものを抽出する。 rule { source_labels = ["__journal__systemd_unit"] target_label = "app" } rule { source_labels = ["__journal_priority_keyword"] target_label = "level" } } // Journaldをソースとしてログを収集する loki.source.journal "journallog" { forward_to = [argument.write_to.value] // 最大どれくらい前のログまで収集するか。過去のログは要らないので回収しない。 max_age = "10m" // ラベルの書き換え設定 relabel_rules = loki.relabel.journallog.rules // 静的に設定するラベルの指定 labels = { job = "loki.source.journal", } }
このモジュールを使ってGrafana Cloudに送信する設定は以下
// Grafana Cloudのログのリモート書き込み先の設定 loki.write "grafanacloud" { endpoint { url = "REMOTE WRITE URL" basic_auth { username = "BASIC AUTH USER" password = local.file.api_key.content } } } // Grafana Cloudのハードリミットに引っかからないよう、大きすぎる/古すぎるログを落とす // Ref: https://grafana.com/docs/grafana-cloud/cost-management-and-billing/understand-your-invoice/usage-limits/#logs-usage-limits loki.process "drop_abnormals" { forward_to = [loki.write.grafanacloud.receiver] stage.drop { longer_than = "255KB" drop_counter_reason = "too long" } stage.drop { older_than = "1h" drop_counter_reason = "too old" } } // メトリクスと同様にinstance名にホストの識別子を入れる loki.relabel "replace_instance" { forward_to = [loki.process.drop_abnormals.receiver] rule { action = "replace" target_label = "instance" replacement = "{{ inventory_hostname }}" } } // 今回はisupipe-goのログがあれば良かったのでこう書いていますが、 // regexを工夫することでpdns.serviceのログも収集できます。 loki.relabel "filter_app" { forward_to = [loki.relabel.replace_instance.receiver] rule { source_labels = ["app"] regex = "^isupipe-go.*$" action = "keep" } } module.file "journallog" { // 先ほどのモジュールまでのファイルパス filename = "/etc/grafana-agent/rivers/journallog.river" arguments { write_to = loki.relabel.filter_app.receiver } }
次にファイルからのログを収集します。単純なログであれば以下の様に書けば収集できます。
argument "write_to" { comment = "Loki remote write target" } // ラベル足したり要らないラベル落としたりとか loki.process "error" { forward_to = [argument.write_to.value] stage.static_labels { values = { app = "mysql", type = "error", } } stage.label_drop { values = ["filename"] } } // MySQLのエラーログを探索させ、存在する場合ターゲットに加える local.file_match "errorlog" { path_targets = [{"__path__" = "/var/log/mysql/error.log.*"}] } // 発見されたエラーログをソースとしてログを送信する loki.source.file "error" { targets = local.file_match.errorlog.targets forward_to = [loki.process.error.receiver] // 過去のデータは要らないので、起動時は常に末尾から読み取っていく。 tail_from_end = true }
先述したようにriverでは様々なモジュール同士の接続を自由に書けるので、このモジュールとjournallogモジュールはログの処理フェーズを共有できます。
module.file "mysql_error_log" { filename = "/etc/grafana-agent/rivers/mysql_error_log.river" arguments { // ラベルの書き換え設定から繋げることで、そこから先を共通化できる write_to = loki.relabel.replace_instance.receiver } }
アクセスログの収集
nginxのアクセスログを元にダッシュボードを表示したいのですが、通常はパスにパラメータなどが入っており統計処理に向いていません。同様のことにnonyleneくんも気付いており、収集時に正規化するという方法を取っていました。
Grafana Agentにおいても同様の処理を行います。前提としてnginxのログ形式は以下の様になっているとします。
log_format main "time:$time_local"
"\thost:$remote_addr"
"\tforwardedfor:$http_x_forwarded_for"
"\treq:$request"
"\tstatus:$status"
"\tmethod:$request_method"
"\turi:$request_uri"
"\tsize:$body_bytes_sent"
"\treferer:$http_referer"
"\tua:$http_user_agent"
"\treqtime:$request_time"
"\tcache:$upstream_http_x_cache"
"\truntime:$upstream_http_x_runtime"
"\tapptime:$upstream_response_time"
"\tvhost:$host"
"\trequest_id:$request_id";
access_log /var/log/nginx/access.log main;
まずは前処理としてnginxのログをパースします。
// nginxのアクセスログをパースして各パラメータをラベルに加える loki.process "access" { // 後段の処理を指定 forward_to = [loki.relabel.access.receiver] stage.static_labels { values = { app = "nginx", type = "access", } } stage.label_drop { values = ["filename"] } // LTSV形式のログ行をパースする。正規表現でバックスラッシュを使いたい時は2つ重ねる。 // 後から気付いたけどこれはjsonにしておけばもっと楽にパースできたので、 // 皆さんはこれをパクらずにnginxにjson形式でログを吐かせてください。 stage.regex { expression = "^time:(?P<time>.*)\\thost:(?P<host>.*)\\tforwardedfor:(?P<forwardedfor>.*)\\treq:(?P<request>.*)\\tstatus:(?P<status>.*)\\tmethod:(?P<method>.*)\\turi:(?P<uri>.*)\\tsize:(?P<body_bytes_sent>.*)\\treferer:(?P<http_referer>.*)\\tua:(?P<http_user_agent>.*)\\treqtime:(?P<request_time>.*)\\tcache:(?P<upstream_http_x_cache>.*)\\truntime:(?P<upstream_http_x_runtime>.*)\\tapptime:(?P<upstream_response_time>.*)\\tvhost:(?P<vhost>.*)\\trequest_id:(?P<request_id>.*)$" } // ログ行からアクセス日時をとりだしてログの記録日時とする stage.timestamp { source = "time" format = "02/Jan/2006:15:04:05 -0700" } // 正規化したいパラメータを抽出する stage.labels { values = { status_normalized = "status", uri_normalized = "uri", } } } local.file_match "accesslog" { path_targets = [{"__path__" = "/var/log/nginx/access.log.*"}] } loki.source.file "access" { targets = local.file_match.accesslog.targets forward_to = [loki.process.access.receiver] tail_from_end = true }
後は実際に本番で実装されているエンドポイントに合わせて設定ファイルを書いて正規化させるだけです。
loki.relabel "access" { forward_to = [argument.write_to.value] // alpが 2XX や 5XX のように表示するのが分かりやすかったので同じ事をする rule { source_labels = ["status_normalized"] regex = "^([0-9])[0-9]+$" replacement = "${1}XX" target_label = "status_normalized" } // クエリパラメータを消す rule { source_labels = ["uri_normalized"] regex = "^(.*)\\?(.+)$" replacement = "$1" target_label = "uri_normalized" } // 以下の様なルールをエンドポイントの数だけ書く。マッチするラベルだけが置き換えられる。 // 本番ではAnsibleでテンプレートを書いておいて自動生成した rule { source_labels = ["uri_normalized"] regex = "^/api/user/[a-zA-Z0-9]+$" replacement = "/api/user/[a-zA-Z0-9]+" target_label = "uri_normalized" } }
Grafanaのダッシュボードではこの送信されたログを再度同じ正規表現でパースし直してレスポンスタイムを取りだし、ラベルとして付与された uri_normalized などを元に行数をカウントしたり最悪レスポンス時間を取り出したりしています。
スロークエリログの収集
MySQLのスロークエリログは、一行ごとに結果が出るのではなく複数行にわたっています。こういったログも設定を書くことで収集できます。
loki.process "slowquery" { forward_to = [argument.write_to.value] stage.static_labels { values = { app = "mysql", type = "slowquery", } } stage.label_drop { values = ["filename"] } // この行から次のこの行までを一つのログとして扱う stage.multiline { firstline = "^#\\sTime:.*$" } // ログをパースする正規表現 stage.regex { expression = "#\\s*Time:\\s*(?P<timestamp>.*)\\n#\\s*User@Host:\\s*(?P<user>[^\\[]+).*@\\s*(?P<host>.*]).*Id:\\s*(?P<id>\\d+)\\n#\\s*Query_time:\\s*(?P<query_time>\\d+\\.\\d+)\\s*Lock_time:\\s*(?P<lock_time>\\d+\\.\\d+)\\s*Rows_sent:\\s*(?P<rows_sent>\\d+)\\s*Rows_examined:\\s*(?P<rows_examined>\\d+)\\n(?P<query>(?s:.*))$" } // 時間をパースしてそのログの時間として設定する stage.timestamp { source = "timestamp" format = "RFC3339Nano" } } local.file_match "slowquery" { path_targets = [{"__path__" = "/tmp/slow_query.log*"}] } loki.source.file "slowquery" { targets = local.file_match.slowquery.targets forward_to = [loki.process.slowquery.receiver] tail_from_end = true }
これは生データのみしか収集できないので、pt-query-digest等も組み合わせることを検討すべきかも知れません。自分たちのチームではpt-query-digestはそれは別途ベンチの度に走らせてリポジトリのIssueに結果を書いており、それで済ませていました。
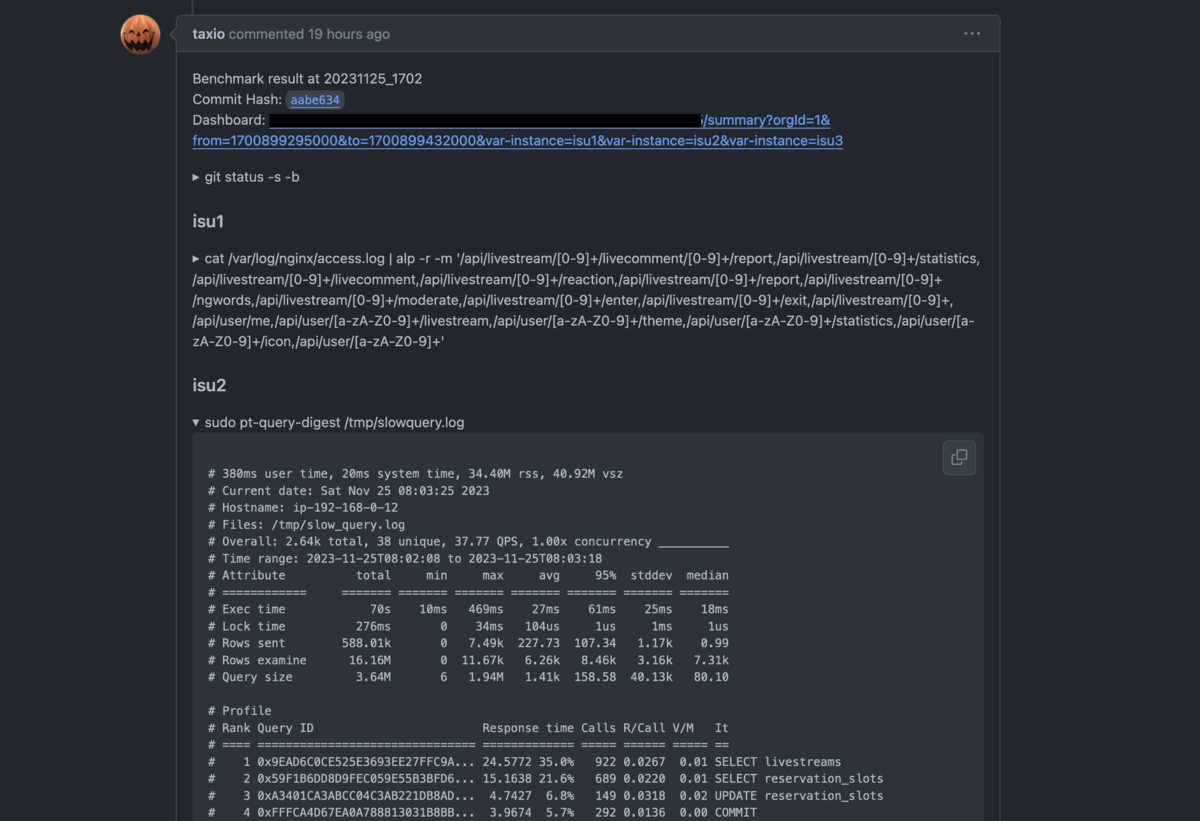
プロファイルデータの取得
Goアプリケーション自体が /debug/pprof エンドポイントを実装していれば、Grafana Agentが書くことはたったこれだけです。実際にはインスタンス名やサービス名、アクセス先のポート番号などは全てAnsibleで動的に埋めています。
pyroscope.write "grafanacloud" { endpoint { url = "REMOTE WRITE URL" basic_auth { username = "BASIC AUTH USER" password = local.file.api_key.content } } } pyroscope.scrape "pprof" { targets = [ {"__address__" = "localhost:8080", "instance" = "{{ inventory_hostname }}", "service_name" = "isupipe"}, ] forward_to = [pyroscope.write.grafanacloud.receiver] scrape_interval = "15s" }
ハマったところ
何でもログのラベルに付与すると死ぬ
Grafana Cloudのログ収集機能には max_global_streams_per_user というハードリミットがかかっています。値は5000です。
これは送信するログに付与するラベルの値の組み合わせの数が相当します。つまり、インスタンスの数が5つあり、それぞれ3種類の値を取るラベルが2つあるとすると、5 × 2 × 3 = 30 のactive streamとなります。
当初、nginxのアクセスログをパースして全てラベルとして付与していましたが、練習の段階でGrafana Agentがこのリミットに引っかかったというエラーを吐いていました。当然です。レスポンスタイムの値、正規化していないURLのパスなどがそのまま入ると、あっという間に5000通りくらいの組み合わせに到達します。
一度に全ログが取得できるわけではない
GrafanaのダッシュボードではTransformという取得したメトリクスを加工する機能が存在しています。そこでGROUP BYしてカウントしたりも可能です。最初期のダッシュボードではLogQLを使ってnginxのアクセスログを全行取ってきてTransform機能でカウントしようとしていましたが、デフォルトでは1000行まで、最大でも5000行までしか一度に取得できず不完全な解析となってしまいました。
最終的には以下の様にLogQLでメトリクスを取ってきて、Transformは最低限になっています。

メトリクスのDPM
送信するログ量自体は競技時間全てを合わせても無料枠を超えませんが、メトリクスをどの頻度で取得するかによって課金額に影響するDPMというパラメータがあります。
これは Data points per minute の略で、Grafana Agentのscrape intervalのデフォルト60秒が1DPMです。これがGrafana Cloud FreeおよびProアカウントのデフォルトです。これを超えた場合、課金額に影響があります。ISUCONでは60秒ごとでは遅すぎるので、競技中のみ15秒に一回スクレイプするようにしました。おそらくこれくらいなら大丈夫ですが、長期間使うインスタンスでは辞めておくべきでしょう。
競技終盤はアクセス数が増えて解析が遅い
これは正規表現でアクセスログをパースしていたことによる可能性を拭えないのですが、競技終盤になるとエンドポイントごとの解析画面は結果の表示に数十秒かかるようになってしまいました。フレームグラフは見れるので、とりあえず開いてクエリを走らせている間にフレームグラフを見るといた感じにしていました。
一位のNaruseJunのチームだとおそらく中盤当たりで使い物にならなくなっていた可能性があります。とはいえほとんどのチームでは自分たちが捌いていたくらいのアクセス数に収まっていると思うので、十分実用的と言えるのではないでしょうか。
完全に同じログ行は重複排除で消える
今回前提としたnginxのログの形式は実はalpのREADMEに書かれているLTSV形式そのままではなく、末尾にrequest_idを追加しています。これはGrafana CloudというかおそらくそのバックエンドになっているLokiのQuerierの制約を回避するためです。
QuerierはLogQLを元に、データを問い合わせて返すコンポーネントです。
https://grafana.com/docs/loki/latest/get-started/components/#querier
the querier internally deduplicates data that has the same nanosecond timestamp, label set, and log message.
これには冗長化のために重複しているログを排除するという機能が実装されています。nginxのログのタイムスタンプの精度は秒単位のため、アクセス数の多いエンドポイントでは容易に全く同じログが吐かれてしまうことがあり、alpの結果とGrafanaダッシュボード上での結果が一致しないことが起きていました。
ログ行自体が完全に一致しなければ異なるログ行として扱われるため、request_id(リクエストごとに一意な値)を出力することで、重複排除によって消えないようにしています。
本番でやったこと・感想
自分が本番でやったことです。
- ~10:40:環境構築・解析基盤の準備
- ~12:00:icon画像をDBから剥がしてX-Accel-Redirectでnginxにサーブさせ、sha256のチェックサムをオンメモリにキャッシュ
- ~13:30:ミドルウェアのチューニングや、moderateHandlerの高速化
- ~15:30:DNS水責め対策に奮闘したが失敗
- ~17:00:DBのレプリケーションをしてリードレプリカを使うようにしたが整合性チェックが通らず失敗
- ~17:30:最終的な複数台構成にした。(nginx, app, pdns)、(DB for app)、(DB for DNS)という構成。
- ~18:00:全ての解析系を止めて再起動試験をし、キャッシュ実装がダメでfailすることに気付く
途中ベンチマークの不具合で大きな変更がちゃんと通るかどうかを検証できず、競技時間伸びないかなとちょっと期待していました。それは叶わず残念。
taxio、shanpuがあらゆるものをメモリに載せようと奮闘している間に自分はDNS水責めの対策をしていました。正直に言ってDNSの知見があまりに乏しく、PowerDNSの設定を変えてDBの向き先を変更してアプリのDBの負荷を減らすのが限界でした。しかし、これも最善手だったとは思っていません。DNSを正しく捌いてしまうことでむしろアプリの負荷が増えていた可能性があります。DNSサーバを自前実装する可能性を一瞬検討し、理解と実装に半日はかかると踏んでDNSを切り捨てる判断をしました。チャレンジすべきだったのかなぁと後悔はつきません。
今回のアプリケーションはread heavyなワークロードなのでリードレプリカが効くかと思ったのですが、自分が途中でミスってレプリケーションそのものに時間がかかったこと、組んだ構成が整合性チェックでどうしても通らなかったことで諦めたのも時間的には痛かったです。後から思えば、もっとオンメモリで処理できました。これは仕事ではないのでSREとしての自分を捨てるべきでした。
あとはキャッシュ実装が速さを優先するあまり初期化や再起動後の状態への意識を失っており、おそらく参加して初のfailでの終了となりました。これはあまりにも痛いです。いくら高スコアを記録しても、failしていては改善しないのと同じです。
良かったところを言うと、自分の役目は基本的に解析基盤を整え、アプリ担当が1コマンドで本番に変更を反映出来る状況にした時点で終わっていると言えなくもないです。後はX-Accel-Redirectでnginxに静的ファイルを捌く処理を移す改善を午前で終わらせられ、午後の余裕がなかったタイミングで取り組む必要が無かったのは心理的に非常に効きました。自分の経験値がまだまだだということがよく分かったので、参加して良かったです。運営の方々、今年もありがとうございました。
まとめ
Grafana Cloudはアプリケーションにできるだけ手を入れず、いつも通りの構成のままインフラ担当が裏から手を回して基盤を構築出来る便利なSaaSです。アプリ本体に手を入れれば、OpenTelemetryで分散トレーシングも可能です。無料枠も大きいので事前の練習などで使うのもおすすめです。
ISUCON12で初の本選出場を果たし、ISUCON13は逆にfailして失格しました。ラノベのセオリーとしては次は優勝のはずなので、来年も頑張ります。